In this article I run through the general process and techniques I use to scrape data from multiple different webpages at once. I will scrape gold prices for all regions and servers for the MMORPG Lost Ark from g2g.com, which is a popular online marketplace for gamers looking to buy in-game items or currency for a variety of games.
Prerequisites
There are a couple things you need before we get started:
- A Chrome webdriver
- The necessary Python libraries installed
Luckily, these two steps are very easy to achieve. A Chrome webriver is an automation tool used to test web applications; however, we are going to use it to automatically navigate through webpages to get where we want them to go. A Chromedriver download can be found here. You will want to download the Chromedriver that matches the version of Chrome you have installed on your system, which can be found by clicking “About Google Chrome” in the “Help” section of your browser.
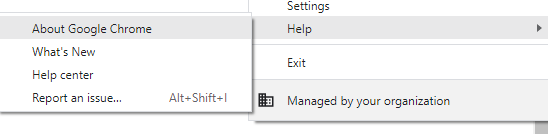
Image by author

Image by author
At the time of writing, I have Chrome version 99.0.4844.82, so I would want to download the Chromedriver for Chrome version 99. Store it in a place you’ll be able to find later, as we’ll need to specify its path in our code.
Next, if you don’t already have them installed on your system, install the following python libraries using either pip install [library name] or conda install [library name] in your console or anaconda navigator. You will need the following libraries:
bs4to parse HTMLand make it readableseleniumto use the Chromedriverpandasfor DataFramesdatetimeto get the time the data is scrapedtimefor pausing on certain webpagesosto write filesreto format expressions
After these have been installed, we are ready to begin!
Getting Started
To get started, we open up a Jupyter notebook or a Python file, and import all the necessary libraries:
from bs4 import BeautifulSoup as bs
from selenium import webdriver
import pandas as pd
from datetime import datetime
import time
import os
import re
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import ElementNotInteractableException
The last five lines help us use our Chromedriver and also search for items in the HTML code for g2g.com more efficiently. I’ll cover these as needed. For now, the line from selenium.webdriver.chrome.options import Options enables us to specify how we want Chrome to be opened. Personally, I like my Chrome instance to be maximized (so I don’t have to maximize the browser manually) and in incognito mode (so my personal history isn’t affected by scraping many, many pages). This is accomplished by the code:
service = Service('insert path to your Chromedriver download')options = Options()
options.add_argument('--incognito')
options.add_argument('start-maximized')driver = webdriver.Chrome(service=service, options=options)
Here, I globally set up a Chromedriver for use in a couple of functions we will write later on. I create a Service object which specifies the path to the Chromedriver, and an instance of Options which enables us to open up Chrome maximized and in incognito mode. Next I open up Chrome by passing our Service and Options instances to webdriver.Chrome(). This will open up Chrome and do absolutely nothing if you were to run the code as-is. Anyway, this completes our initial setup. Nowwe shall move on to the scraping.
First Scraping Steps
Before we get to scraping gold prices there are a few obstacles we must overcome. One of these obstacles is the fact that there are 62 separate servers to buy gold from, and they all have different URLs. See below picture from G2G: World Leading Digital Marketplace Platform.
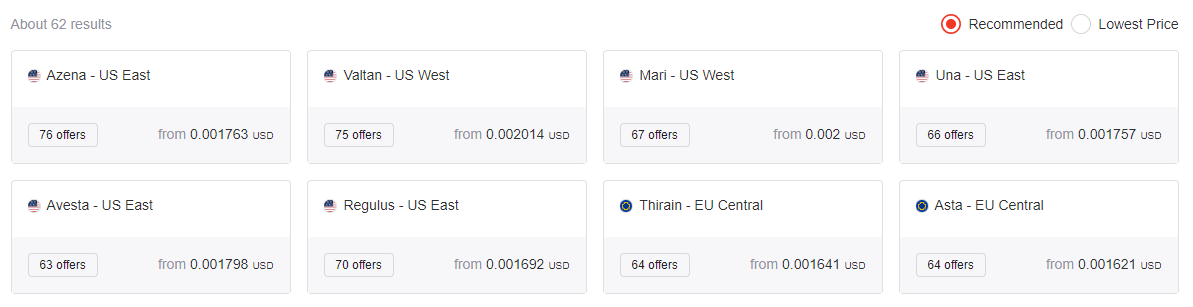
Each one of these servers has a different URL we’ll need to visit! Image by author
Let’s get the URLs to all of these servers, because we want to scrape data from all of them. We want to view the HTML code of the page to see where to find them. In Chrome, we simply navigate to the appropriate URL at G2G: World Leading Digital Marketplace Platform, and right click on the page and hit inspect. Next, we want to view the HTML code of an element on the page, specifically the offer boxes, so we can see where to find the URL leading to that server’s gold prices. In Chrome, we can inspect specific elements by hitting the button in the very top left corner of the sidebar and simply hovering over the element we want to see the HTML code of.
Select the button to select an element. Image by author
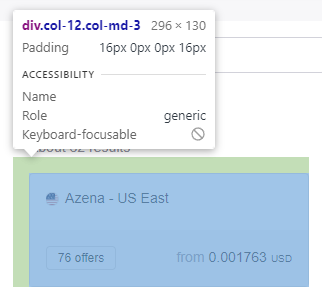
Hover over the item we want. Image by author
When clicking on the item in the above picture, the HTML code for that element is revealed to us in the sidebar. Upon inspection of the code, we can see that there is only one URL in the section of HTML code we’re looking at, and all of the elements for the servers have similar code, as poorly highlighted in the picture below.
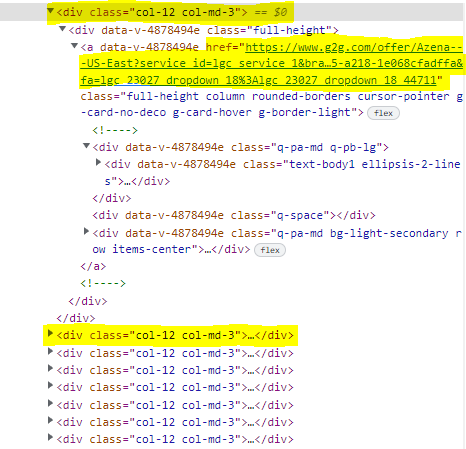
The servers are separated by a ‘div’ element with class ‘col-12 col-md-3’. Image by author
Now we are ready to scrape the URLs. After initializing our Chromedriver from earlier, I execute this code:
URL = 'https://www.g2g.com/categories/lost-ark-gold'# initialize an empty list to store the URLs in
links = []driver.get(URL)
time.sleep(5) # my internet is slow, so this pauses to load it in
html = driver.page_source
soup = bs(html, features='html.parser')boxes = soup.find_all('div', class_='col-12 col-md-3')
for box in boxes:
links.append(box.find('a', href=True)['href'])
Above, we tell our driver to go to the URL that we’ve been inspecting, and allow it to load (due to my slow internet, this may not be necessary for you) using the time.sleep(5) line. Next, we get the HTML of the webpage using html = driver.page_source ; however, if we printed the HTML as-is it would be a jumbled, incomprehensible mess of text. Thus, we use BeautifulSoup4 to parse the HTML code and make it more readable for us. For the ‘features’ argument, you can use your preferred HTML parser, but I like to use html.parser for simplicity. After this, the line boxes = soup.find_all(...) will return a list of all of the ‘div’ elements that have a class equal to ‘col-12 col-md-3’, which we identified as the HTML code of each server on the Lost Ark gold-selling page. We then loop through each of the ‘box’ elements, pulling out the URLs for each server we come across.
Scrolling down to the bottom of the page, we see that the servers are listed on two different pages:

Image by author
To combat this I use a brute force method, since it is reasonable to assume that the number of pages will not increase in the near future. I simply repeat the above process for the second page of game servers:
URL2 = URL + '?page=2'
driver.get(URL2)
time.sleep(5)
html = driver.page_source
...
This brute force method will do for the purposes of this article. Now that we have the URLs for each server, we will go on to how to collect the data.
Navigating Multiple Paginated Pages
To keep things simple, I will demonstrate how to scrape all of the gold prices for one server in particular. If you are interested in how I navigate through every single server and handle a few exceptions that occur, you can view the original code to this project here.
We are going to look at the gold prices for Azena, which should be the first (zeroth, in Python) link in the ‘links’ list, not linked list. You can easily get the link by setting azena_link = links[0]. First, let’s take a look at how the page is set up and how we will plan to scrape the data. Navigating to the page with the gold listings, we see they are all listed in a table, separated by four different pages. Like we did with the links, we want to identify the HTML code for each of the listings. This time, we also want our Chromedriver to navigate between pages for us so that we don’t have to do it manually.
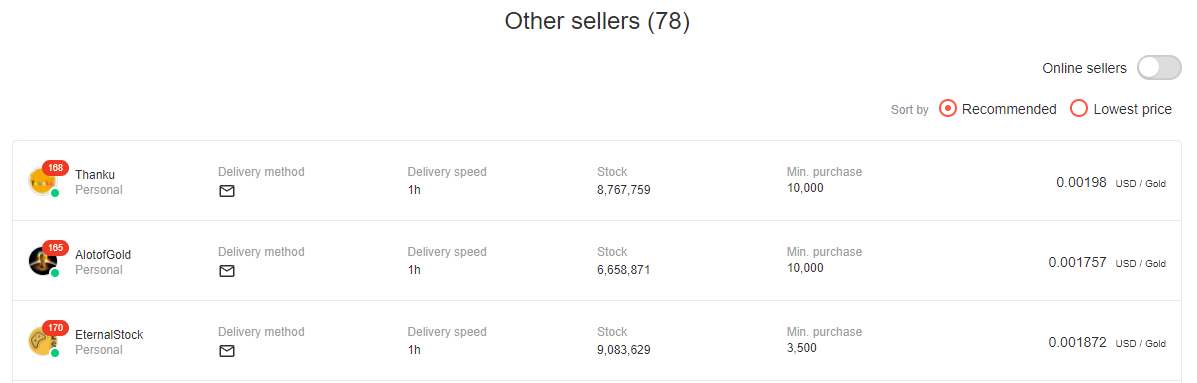
Image by author
…

The bottom indicate we have four pages to navigate through. Image by author
Above we see that this particular server, at least at the time of writing, has four pages of gold prices. In order to navigate through all four pages, we will want to collect the data on the initial page, click the next page button, collect the data on the second page, click the button, etc… Thus, we need to click the button to go to the next page until it doesn’t show up anymore, while collecting the data we want along the way. To do this, I typically use the helper function below:
def check_exists_by_xpath(driver, xpath):
try:
driver.find_element(By.XPATH, xpath)
except NoSuchElementException:
return False
return True
In this function, I check if an element exists by using its XPATH, which can be found by inspecting the HTML code similar to what we did earlier. Simply right click on the element’s HTML code, and there will be an option to copy its XPATH, shown below:
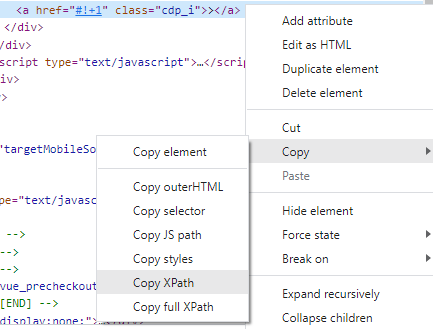
Image by author
In our case, we are specifically looking for the button that contains the text ‘>’. So we will want to check for the existence of that button using our function:
if check_exists_by_xpath(driver, "//a[contains(text(), '>')]"):
element = driver.find_element(By.XPATH, "//a[contains(text(), '>')]")
driver.execute_script('arguments[0].scrollIntoView();', element)
driver.execute_script('window.scrollBy(0, -200);')
element.click()else:
print('No next page!')
In the above code block, we check if the button exists using the helper function, which returns True if it exists and False if not. If the button does exist, we scroll to its location by executing a couple of script lines, and then we click on it to head to the next page. Now, we can simply execute a chunk of code similar to this until the button does not exist, in which case we will see the message ‘No next page!’ Of course, we will want to scrape the gold prices (and whatever other information you want) along the way.
We’re basically done! Now all we have to do is actually collect the data. Similar to what we did before, inspect any gold listing to see the structure of its HTML code.
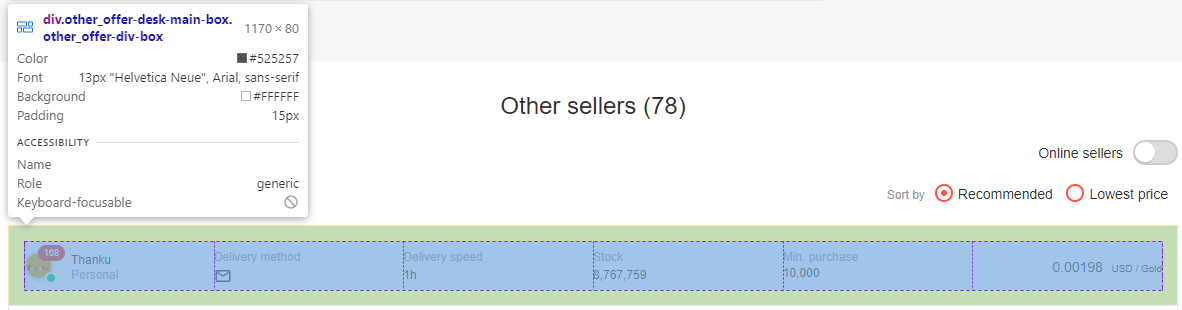
Image by author
Upon inspection, we see that each of these ‘offer boxes’ is contained within a ‘div’ with ‘class’ equal to ‘other_offer-desk-main-box other_offer-div-box’. We will want to use BeautifulSoup4 to search for these specifically and store them in a list.
offer_boxes = soup.find_all('div', class_='other_offer-desk-main-box other_offer-div-box')
And now we navigate through each of the offer boxes and pull out the data that we want.
for box in offer_boxes:
name = box.find('div', class_='seller__name-detail').text.strip()
price = box.find('span', class_='offer-price-amount').text.strip()
price = re.sub(',', '', price)
price = float(price)
In the above code chunk, I pull out the seller’s name and the price at which they are selling gold. I use regex to ensure the price has no unnecessary characters and turn it into a float value. And that’s it! In my original code, I store the values in lists and convert them into pandas DataFrames for later conversion to .csv files. How you structure your data and what you want to collect is up to you. Again, if you want to view my code in more detail you can view the original code here. You can view the dashboard I made for this project here.