Here’s A Funny Story
I am sure you are familiar with the prices of graphics cards lately, they are pretty darn high… at the peak of the GPU shortage I find my self wanting to get a new one. So what do I do? I check Amazon and Newegg for prices (and oh boy it was tedious). Not only I was seeing prices getting higher and higher, it was just a boring task that I thought, as a programmer — I can do better than that.
So Here We Are
Still did not get a new GPU, but I managed to scrape every website in existence, and soon you will too. For this tutorial we will scrape the price of RTX 3070 Ti (not affiliated, sadly) from Amazon with the module Beautiful Soup.
Let’s Get Started
For anyone not familiar with Beautiful Soup, it is a Python library for pulling data out of HTML and XML files. basically, we can easily extract the contents of a website and then use Beautiful Soup to get exactly what we need.
To get the page content, we are going to use the module Requests, which is an elegant and simple HTTP library for Python.
If you do not have these modules installed, open a new Command Prompt (CMD) window and type in the following:
pip install beautifulsoup4
pip install requests
Now that we have these modules installed, let’s go ahead import them so we could use them in our project:
from bs4 import BeautifulSoup
import requests
Now, we need to get the URL for the Requests module. For this tutorial, I chose the RTX 3070 Ti Amazon page but the world is your oyster and you are free to choose which ever page you want. But I would highly recommend using the same webpage as me so you can follow the tutorial more smoothly.
URL = "https://www.amazon.co.uk/Gigabyte-GeForce-3070-GAMING-Graphics/dp/B095X6RLJW/ref=sr_1_1?keywords=rtx+3070&qid=1650485234&sr=8-1"
Now, we need to add a user agent. This ensures that the target website we are going to web scrape doesn’t consider traffic from our program as spam and gets blocked. Some websites like Amazon, block spam so it won’t work without using a user agent.
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}
Finally, we can get the page content with the Requests module and use beautiful soup to make beautiful soup out of it!
page = requests.get(URL, headers=headers)
soup = BeautifulSoup(page.content, "html.parser")
Let’s Scrape Data!
Now, that the soup is ready (yum!), we can start scraping stuff. We are going to find the price for the GPU. We need to find the specific element that holds the price. Double click on the price in the website and press inspect.
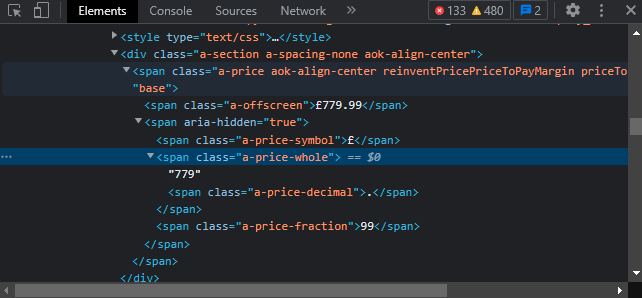
We need to get this specific element. We can see the class is: “a-price-whole” and the element type is a Span, so we use the find function in order to get that element in our code.
price = soup.find("span", class_="a-price-whole")
Alright! We have the element in our code and all that is left is just to print the content of the element.
print(price.text)OUTPUT: 779.
``
Congratulations, you’ve successfully scraped Amazon for data. Now, as a challenge, go ahead and try to scrape the same product just from Newegg.
# That’s It?
This is the foundation for web scraping. For my project, I added an if statement that if the GPU price falls under a certain amount I would get notified by email with the link so I could purchase immediately. The program would start every morning, automatically saving me a few seconds a day. You can even scrape data from multiple sites and compare between them. As I always say, the world is your oyster. Happy scraping ya all!
If you enjoy this type of content, make sure you check out my blog at: https://codeyluck.com/