Stacking là kỹ thuật kết hợp các mô hình trong học máy nhằm nâng cao hiệu quả dự đoán. Bằng cách sử dụng một mô hình “meta” để tổng hợp các kết quả từ các mô hình cơ bản, Stacking giúp cải thiện độ chính xác của hệ thống AI. Trong bài viết này, chúng tôi sẽ giải thích chi tiết về Stacking, cách thức hoạt động và các bước triển khai để đạt hiệu quả cao nhất.
Bạn có thể tìm hiểu về Stacking trong bài viết dưới đây hoặc tìm hiểu chi tiết thêm về các bước triển khai mô hình Stacking tại: Stacking là gì? Tìm hiểu về Stacking trong Machine Learning
Stacking Trong Học Máy Là Gì?
Stacking, còn được biết đến với tên gọi Stacking Generalisation (Tổng quát hóa Chồng lớp), là một phương pháp kỹ thuật tiên tiến trong lĩnh vực học máy. Bản chất của Stacking là việc tổng hợp nhiều mô hình học máy riêng lẻ, sử dụng kết quả dự đoán của chúng như những đặc trưng đầu vào (thường được xem xét dựa trên “trọng số” hoặc mức độ đóng góp) để huấn luyện một mô hình cấp cao hơn. Mục tiêu cuối cùng là tạo ra một mô hình tổng hợp mới có độ chính xác vượt trội hơn và khai thác được thế mạnh của các mô hình thành phần.
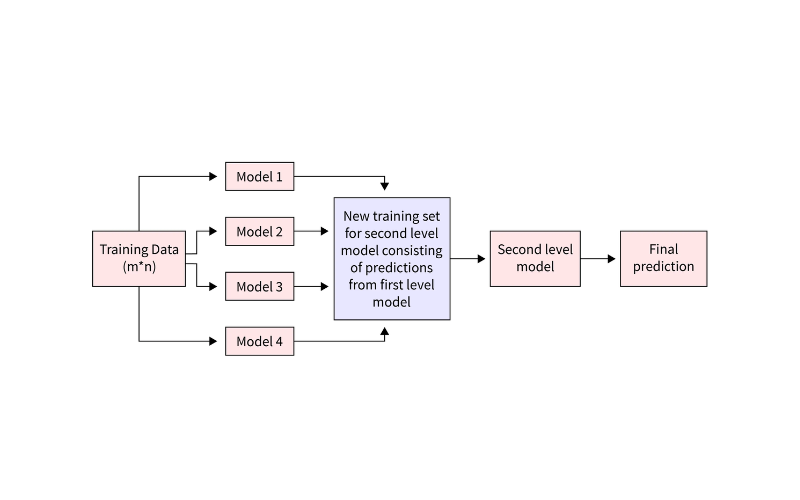
Có thể hình dung kiến trúc Stacking như một cấu trúc gồm hai tầng chính: tầng đầu tiên (cấp 0) bao gồm tập hợp các mô hình cơ sở (base models) đa dạng, và tầng thứ hai (cấp 1) là một mô hình tổng hợp (meta-model) có nhiệm vụ đưa ra dự đoán cuối cùng dựa trên đầu ra của tầng trước.
Nguyên tắc nền tảng của Stacking xuất phát từ thực tế rằng một bài toán học máy phức tạp thường có thể được tiếp cận hiệu quả hơn bằng cách sử dụng đồng thời nhiều loại mô hình khác nhau. Mỗi mô hình này có thể học tốt một khía cạnh hoặc một phần riêng biệt của không gian vấn đề, nhưng không mô hình đơn lẻ nào có thể bao quát hoàn hảo toàn bộ. Stacking ra đời chính là để giải quyết bài toán này, học cách kết hợp tối ưu những “góc nhìn” riêng lẻ đó.
Về bản chất, Stacking là một kỹ thuật nhằm nâng cao năng lực dự đoán của trí tuệ nhân tạo thông qua việc kết hợp nhiều mô hình học máy khác nhau thành một hệ thống thống nhất. Quy trình này vận hành bằng cách thu thập các dự đoán từ mỗi mô hình cơ sở, sau đó cung cấp chúng làm đầu vào cho một “meta-model” (mô hình tổng hợp) cuối cùng. Meta-model này sẽ học cách phối hợp các dự đoán đó, phát huy tối đa điểm mạnh và hạn chế điểm yếu của từng mô hình thành phần.
Lấy ví dụ cụ thể: giả sử chúng ta có một mô hình nhận diện hình ảnh rất giỏi trong việc xác định các loài động vật nhưng lại kém hiệu quả khi gặp hình ảnh xe cộ. Ngược lại, một mô hình khác lại xuất sắc trong việc nhận diện xe cộ nhưng lại gặp khó khăn với động vật. Khi áp dụng Stacking, meta-model có thể học được rằng nên “tin tưởng” dự đoán của mô hình chuyên về động vật khi đối mặt với ảnh động vật, và ưu tiên kết quả từ mô hình chuyên về xe cộ khi xử lý ảnh xe cộ.
Sự kết hợp thông minh các “chuyên môn” riêng biệt này cho phép mô hình Stacking tổng hợp đạt được hiệu suất tổng thể cao hơn đáng kể so với bất kỳ mô hình đơn lẻ nào hoạt động độc lập. Bằng cách bù đắp cho những điểm yếu cố hữu của từng mô hình thành phần, Stacking tạo ra kết quả đầu ra cuối cùng chính xác hơn và có độ tin cậy (robustness) cao hơn.
Tầm Quan Trọng Của Kỹ Thuật Stacking
Stacking đóng một vai trò quan trọng trong lĩnh vực Trí tuệ Nhân tạo (AI) bởi nó cho phép các mô hình khác nhau khai thác và bổ sung điểm mạnh lẫn nhau, từ đó đạt được năng lực tổng thể vượt trội. Thông qua việc kết hợp các nguồn “chuyên môn” đa dạng, kỹ thuật này hiệu quả trong việc bù đắp những hạn chế của từng mô hình riêng lẻ và nâng cao đáng kể hiệu suất chung của toàn hệ thống.
Phương pháp tiếp cận mang tính “hợp tác” này giúp kiến tạo nên các hệ thống AI có khả năng đưa ra kết quả dự đoán chính xác hơn và đáng tin cậy hơn. Stacking thúc đẩy sự tiến bộ của AI bằng cách tích hợp nhiều góc nhìn phân tích khác nhau về cùng một vấn đề, dẫn đến khả năng ra quyết định tốt hơn trong các ứng dụng then chốt như thị giác máy tính hay xử lý ngôn ngữ tự nhiên.
Thay vì chỉ dựa dẫm vào hiệu năng của một mô hình đơn lẻ, Stacking thực hiện việc hợp nhất sức mạnh của nhiều thuật toán khác biệt, tạo ra các giải pháp tổng thể mạnh mẽ và toàn diện hơn. Khả năng kết hợp thông minh các thế mạnh này chính là một yếu tố then chốt giúp khai thác tối đa tiềm năng của Trí tuệ Nhân tạo.
Kiến Trúc Phân Tầng Của Mô Hình Stacking
Một mô hình Stacking điển hình trong học máy thường có cấu trúc phân tầng như sau:
- Dữ liệu (Data): Tập dữ liệu ban đầu được phân chia thành hai phần chính: tập dữ liệu huấn luyện (training data) và tập dữ liệu kiểm tra (test data).
- Các Mô hình Cấp 0 (Level 0 Models / Base Models): Đây là tập hợp các mô hình học máy cơ sở, đa dạng về thuật toán, được huấn luyện độc lập trên tập dữ liệu huấn luyện để đưa ra các dự đoán ban đầu.
- Các Dự đoán Cấp 0 (Level 0 Predictions / Base Predictions): Là kết quả đầu ra (dự đoán) được tạo ra bởi các mô hình Cấp 0 khi áp dụng chúng trên chính tập dữ liệu huấn luyện ban đầu. Những dự đoán này sẽ được sử dụng làm đặc trưng đầu vào cho tầng tiếp theo.
- Mô hình Cấp 1 (Level 1 Model / Meta-Model): Đây là mô hình tổng hợp, có nhiệm vụ học cách kết hợp tối ưu các dự đoán từ tất cả các mô hình Cấp 0. Nó được huấn luyện dựa trên các Dự đoán Cấp 0.
- Dự đoán Cấp 1 (Level 1 Predictions / Final Predictions): Là kết quả dự đoán cuối cùng của toàn bộ hệ thống Stacking. Mô hình Cấp 1, sau khi được huấn luyện trên các Dự đoán Cấp 0 (từ dữ liệu huấn luyện), sẽ được sử dụng để đưa ra dự đoán trên các Dự đoán Cấp 0 tương ứng được tạo ra từ dữ liệu kiểm tra.
Quy Trình Vận Hành Của Stacking trong học máy
Phương pháp Stacking hoạt động dựa trên việc phối hợp kết quả đầu ra từ nhiều mô hình khác nhau nhằm cải thiện chất lượng dự đoán cuối cùng. Dưới đây là các bước cơ bản trong quy trình này:
- Chuẩn bị Dữ liệu: Tập dữ liệu gốc được chia thành bộ huấn luyện và bộ kiểm tra. Bộ huấn luyện dùng để xây dựng các mô hình thành phần, còn bộ kiểm tra được giữ lại để đánh giá hiệu suất cuối cùng của mô hình Stacking tổng hợp.
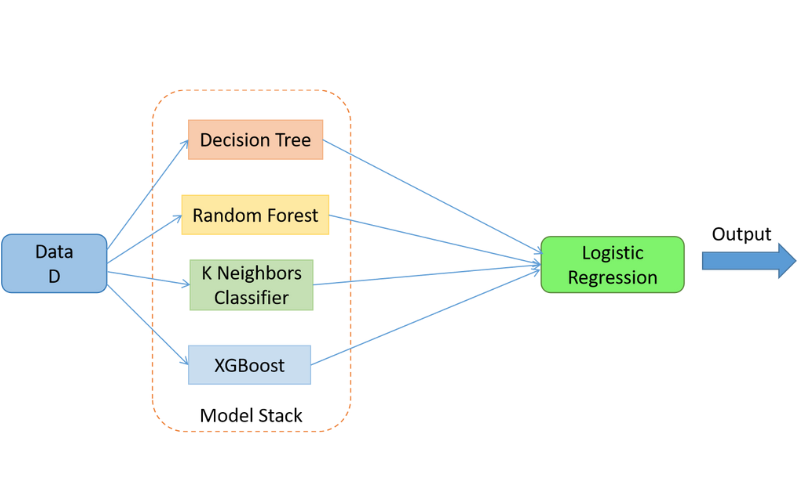
- Huấn luyện các Mô hình Cơ sở (Base Models): Tiến hành huấn luyện một tập hợp gồm nhiều mô hình cơ sở khác nhau (ví dụ: Cây quyết định, Hồi quy Logistic, Máy vector hỗ trợ - SVM, v.v.) một cách độc lập. Các mô hình này nên được lựa chọn đa dạng về bản chất thuật toán để đảm bảo thu được nhiều “góc nhìn” khác nhau về dữ liệu. Chúng đều được huấn luyện trên cùng một bộ dữ liệu huấn luyện.
- Tạo Dự đoán từ Mô hình Cơ sở (Generate Base Predictions): Sau khi huấn luyện xong, sử dụng từng mô hình cơ sở này để đưa ra dự đoán trên chính bộ dữ liệu huấn luyện mà chúng vừa học. Tập hợp các dự đoán này (mỗi cột tương ứng với dự đoán của một mô hình cơ sở) sẽ hình thành nên một tập dữ liệu mới, nơi các cột là các “đặc trưng” mới, phản ánh cách mà mỗi mô hình cơ sở “nhìn nhận” dữ liệu gốc.
- Huấn luyện Mô hình Tổng hợp (Meta-Model): Xây dựng và huấn luyện một mô hình tổng hợp (meta-model hay mô hình Cấp 1). Mô hình này lấy các đặc trưng mới (chính là các dự đoán từ mô hình cơ sở ở bước 3) làm đầu vào (có thể kết hợp thêm các đặc trưng gốc ban đầu nếu cần). Meta-model, thường là một thuật toán tương đối đơn giản như Hồi quy Tuyến tính hoặc Hồi quy Logistic, sẽ học cách tìm ra mối liên hệ và cách kết hợp tối ưu các kết quả đầu ra từ các mô hình cơ sở để đưa ra dự đoán chính xác nhất.
- Tạo Dự đoán Cuối cùng: Khi có dữ liệu mới cần dự đoán (ví dụ: bộ dữ liệu kiểm tra), đầu tiên, đưa dữ liệu này qua tất cả các mô hình cơ sở đã huấn luyện để thu được các dự đoán tương ứng từ chúng. Sau đó, cung cấp những dự đoán này làm đầu vào cho meta-model đã được huấn luyện ở bước 4. Kết quả đầu ra của meta-model chính là dự đoán cuối cùng của toàn bộ hệ thống Stacking.
Nhờ cấu trúc đa tầng này, Stacking có khả năng đạt được hiệu suất dự đoán vượt trội bằng cách khai thác hiệu quả thế mạnh riêng biệt của từng mô hình thành phần khác nhau.