
If you want to get some restaurant comments corpus to do analysis or text mining stuff, the first thing that comes to your mind is probably Google Maps and Yelp.
Yelp is a well-known restaurant information and review platform. Compare to Google Maps, Yelp is more difficult to scrap reviews. Therefore, in this tutorial, I will share how to smoothly crawl Yelp reviews, and hope you will enjoy it!
Advance Preparation
- A little bit of Python
- Understand the structure of HTML
Let’s get started!
About XPath
XPath uses path expressions to select nodes or node-sets in an XML document. XPath also can express the HTML DOM, we can use it to find the correct information on the website.
How to get element XPath?
First, right-click on the web page and choose Inspect, and it will show the source code of the web.
Second, press Ctrl+U (Windows PC) or Command+Option+U (Mac) then select an element on the page. For example, if we want to get the XPath of a restaurant name, you can move the cursor over the restaurant name, and the source code panel will grab the corresponding element.
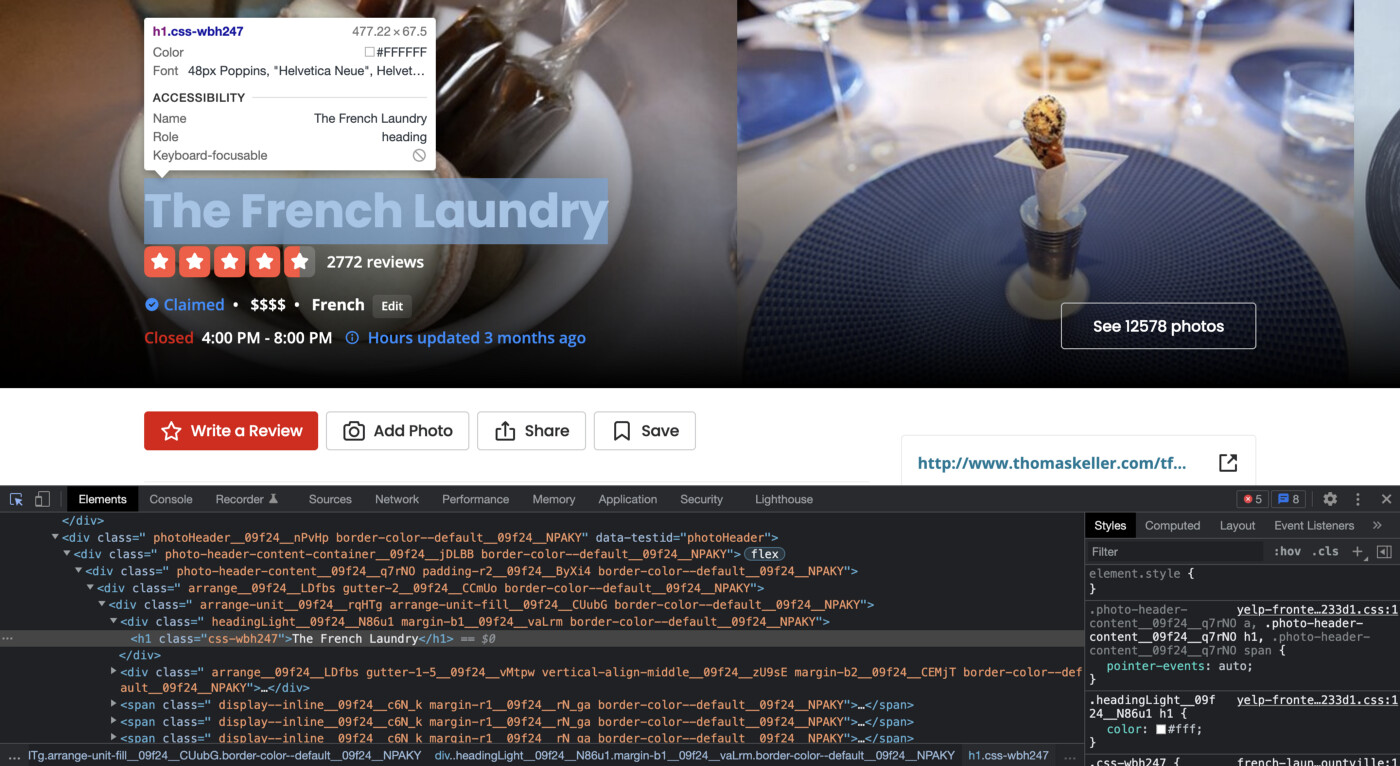
Finally, right-click on the HTML element and choose Copy > Copy full XPath to get the XPath of the restaurant name successfully. It may show
/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/div[1]/h1
Web Analysis and Design Crawl Strategy
In this crawl mission, we focus on how to scrape restaurant’s reviews. Absolutely, we also need to get restaurant’s name.
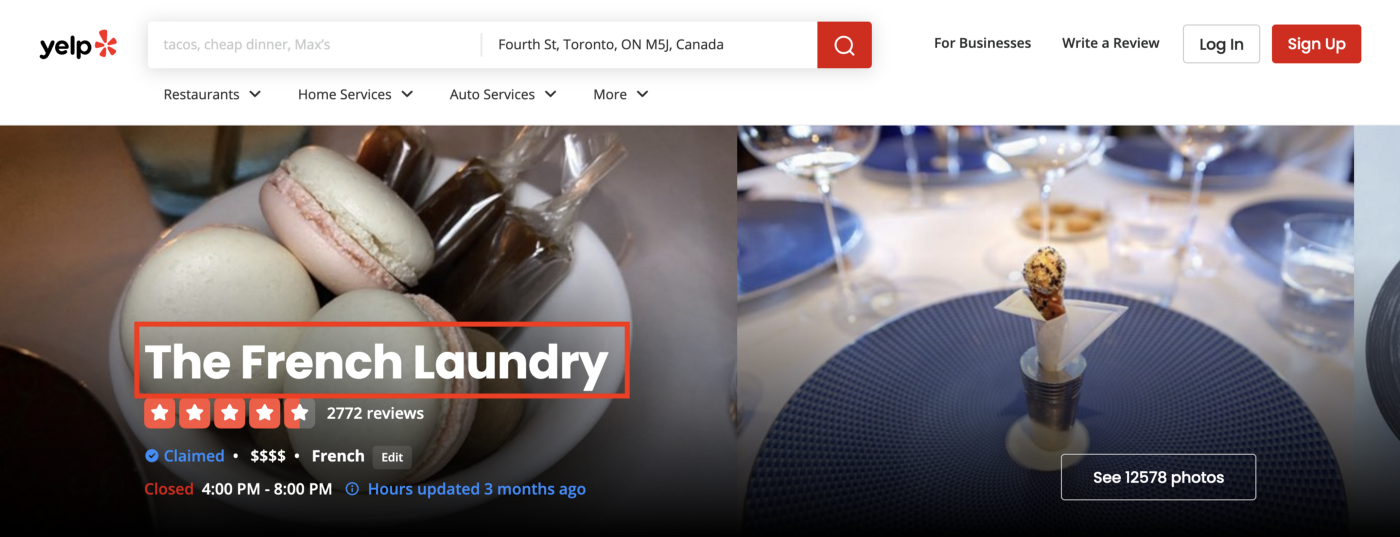
In the comment section, we would like to get the author name, rating, published date and comment content.
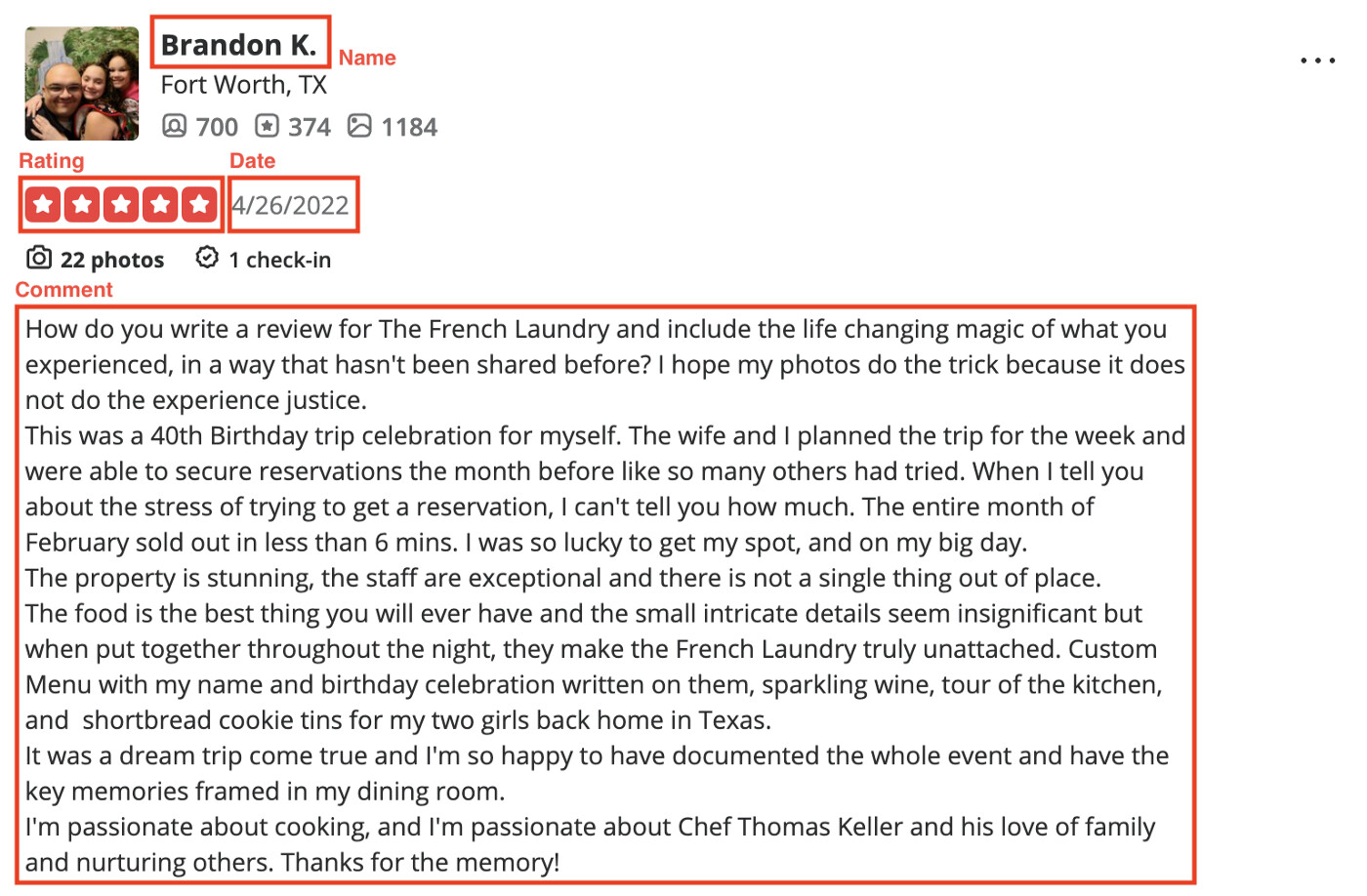
At the same time, we also note that the site will have different XPath for different information presentation, which may need to be considered for dynamic adjustment.
The last and the most important thing is that we need to be able to change pages automatically during the crawling process. So we will need to know the total number of pages in the comment and the location of the “next page button” element.

Based on the above structural analysis, we define the following methods in our script.
- get_max_page: get the total page number of reviews
- next_page_button: find the element of the clicking next page button
- scrap_review: the main function of scrape restaurant’s reviews
- organize_info: concat all page dict-lsit into one list
Let’s Code
Before running the script, you need to download the chromedriver that matches your version of chrome.
import os
import csv
import time
from bs4 import BeautifulSoup
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ActionChains
from selenium.webdriver.support import expected_conditions as EC
DRIVER_PATH = './chromedriver'
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
def retrive_review(parser):
''' Retrive real-time reviews for each dynamic source page.
- Params: {parser} HTML page
- Return: {dict-list} restaurant reviews
'''
info_list = []
reviews = []
ratings = []
dates = []
name = parser.xpath('/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/div[1]/h1/text()')
li_list = []
i = 0
while li_list==[] and i<5:
seed = ''
if i > 0:
seed = '[{}]'.format(i)
template = '/html/body/yelp-react-root/div[1]/div[4]/div/div/div[2]/div/div[1]/main/div[2]/section{}/div[2]/div/ul/li'.format(seed)
li_list = parser.xpath(template)
i += 1
for li in li_list:
username = li.xpath('./div/div[1]/div/div[1]/div/div/div[2]/div[1]/span/a/text()')
review = li.xpath('./div/div[3]/p/span/text()')
rating = li.xpath('./div/div[2]/div/div[1]/span/div/@aria-label')
date = li.xpath('./div/div[2]/div/div[2]/span/text()')
if not username: # Qype User
username = li.xpath('./div/div[1]/div/div[1]/div/div/div[2]/div[1]/span/text()')
if not review:
review = li.xpath('./div/div[4]/p/span/text()')
info_dict = {
"name": name[0],
"username": username[0],
"rating": rating[0].replace(' star rating', ''),
"date": date[0],
"review": review[0]
}
info_list.append(info_dict)
return info_list
def get_max_page(parser):
''' Get the total page number of reviews, for further click iteration.
- Params: {parser} HTML page
- Return: {int} total page number
'''
dom = []
i = 0
while dom==[] and i<5:
seed = ''
if i > 0:
seed = '[{}]'.format(i)
template = '/html/body/yelp-react-root/div[1]/div[4]/div/div/div[2]/div/div[1]/main/div[2]/section{}/div[2]/div/div[4]/div[2]/span'.format(seed)
dom = parser.xpath(template)
i += 1
print(dom[0].text)
num = int(dom[0].text.split(' of ')[-1])
return num
def organize_info(info):
''' Concat all dictionaries into one single list. '''
final_info = []
for i in info:
for j in i:
final_info.append(j)
return final_info
def next_page_button(parser):
''' Find the element of the clicking next page button.
- Params: {parser} HTML page
- Return: {str} button xpath
'''
button_xpath = ''
dom = []
i = 0
while dom==[] and i<5:
seed = ''
if i > 0:
seed = '[{}]'.format(i)
button_xpath = '/html/body/yelp-react-root/div[1]/div[4]/div/div/div[2]/div/div[1]/main/div[2]/section{}/div[2]/div/div[4]/div[1]/div/div'.format(seed)
dom = parser.xpath(button_xpath)
i += 1
click_point = len(dom)
click_xpath = button_xpath + str([click_point]) + '/span/a/span'
return click_xpath
def scrap_review(url):
''' Scrape reviews of one restaurant
- Params: {str} resturant url
'''
driver = webdriver.Chrome(executable_path=DRIVER_PATH, options=chrome_options)
res = driver.get(url)
time.sleep(5)
parser = etree.HTML(str(driver.page_source).replace('<br>', '\n').replace('</br>', '\n'))
total_page_num = get_max_page(parser)
next_page_xpath = next_page_button(parser)
info_list = []
for i in range(total_page_num):
dict_ = retrive_review(parser)
info_list.append(dict_)
print("-> Page", i+1, "success!")
if total_page_num > 1:
element = driver.find_element(by=By.XPATH, value=next_page_xpath)
webdriver.ActionChains(driver).move_to_element(element).click(element).perform()
time.sleep(5)
parser = etree.HTML(str(driver.page_source).replace('<br>', '\n').replace('</br>', '\n'))
driver.quit()
return info_list
Great, we complete the script. You can call the function to easily scrape reviews!
URL = 'https://www.yelp.com/biz/claude-bosi-at-bibendum-london'
total_info = scrap_review(URL)
total_info = organize_info(total_info)
Hi, this is Jenson, I’m a developer from Taiwan.
I specialize in web development, data analysis, and business software development. I will share more about programming technology and my coding life.
If this tutorial is helpful to you, please click on the clap and share your thoughts with me, thank you!