Queue là một cấu trúc dữ liệu tổ chức dữ liệu theo một thứ tự nhất định, trong đó phần tử được thêm vào đầu này (thường gọi là “rear” hoặc “back”) và bị xóa khỏi đầu kia (thường gọi là “front”). Điều này tạo ra một luồng xử lý tuần tự theo thời gian nhập.

Trong lập trình, thuật ngữ “cấu trúc dữ liệu” dùng để chỉ cách tổ chức và lưu trữ dữ liệu trong máy tính. Nó quyết định cách dữ liệu được truy cập và thao tác. Queue là một trong những cấu trúc dữ liệu cơ bản và quen thuộc nhất.
Hãy tưởng tượng một hàng người đang chờ mua cà phê. Người đến trước sẽ được phục vụ trước. Người mới đến sẽ đứng ở cuối hàng. Đây chính xác là cách Queue hoạt động: người/phần tử nào “đến” trước sẽ được “xử lý”/lấy ra trước.
Khái niệm Queue đơn giản nhưng mạnh mẽ. Nó cung cấp một mô hình rõ ràng để quản lý các nhiệm vụ hoặc dữ liệu cần được xử lý theo trình tự thời gian nhập. Điều này đặc biệt hữu ích trong các tình huống cần đảm bảo công bằng hoặc duy trì thứ tự.
Việc nắm vững định nghĩa này là bước đầu tiên để hiểu các khía cạnh phức tạp hơn của Queue. Nó đặt nền móng cho việc tìm hiểu nguyên lý hoạt động và các thao tác sau này.
Nguồn tham khảo: Queue là gì? - InterData
Nguyên lý hoạt động cốt lõi của Queue: FIFO (First-In, First-Out)
Nguyên lý hoạt động chính và đặc trưng nhất của Queue là FIFO, viết tắt của “First-In, First-Out”. Điều này có nghĩa là phần tử được thêm vào Queue đầu tiên sẽ là phần tử đầu tiên được lấy ra khỏi Queue.
Hãy nghĩ lại ví dụ về hàng người. Người đầu tiên xếp hàng sẽ là người đầu tiên được phục vụ và rời khỏi hàng. Những người đến sau sẽ chờ đến lượt mình, theo đúng thứ tự họ đã xếp vào hàng. Thứ tự vào là thứ tự ra.
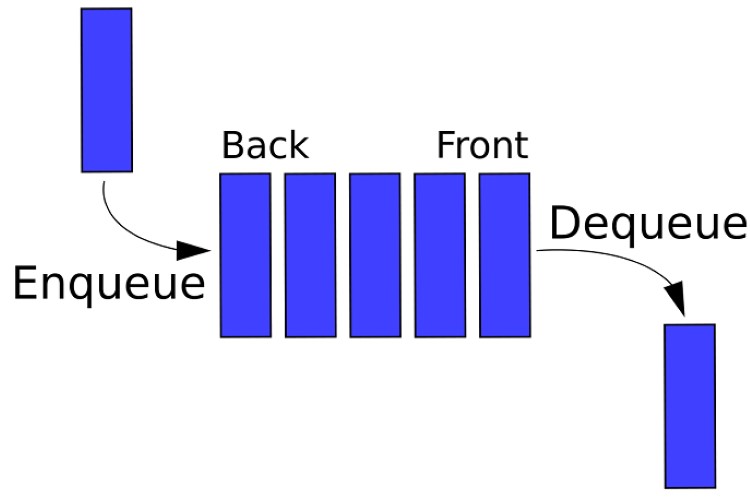
Trong ngữ cảnh lập trình, khi bạn “enqueue” (thêm vào) một phần tử vào Queue, nó sẽ chờ ở cuối hàng. Khi bạn “dequeue” (lấy ra) một phần tử, hệ thống sẽ luôn lấy phần tử đang đứng đầu hàng – tức là phần tử đã ở trong Queue lâu nhất.
Nguyên tắc FIFO phân biệt Queue với các cấu trúc dữ liệu khác như Stack (sẽ được đề cập sau). Nó đảm bảo rằng không có phần tử nào bị “mắc kẹt” ở phía sau vô thời hạn, miễn là các thao tác dequeue vẫn diễn ra.
Sự tuân thủ nghiêm ngặt nguyên tắc FIFO là lý do khiến Queue phù hợp cho nhiều ứng dụng cần xử lý các mục theo thứ tự thời gian đến. Nó tạo ra một dòng chảy dữ liệu công bằng và dễ dự đoán.

Các thao tác cơ bản trên Queue mà bạn cần biết
Để làm việc với Queue, có một số thao tác cơ bản mà bạn cần nắm vững. Các thao tác này cho phép chúng ta thêm, bớt và kiểm tra trạng thái của hàng đợi. Hiểu rõ chúng là chìa khóa để sử dụng Queue hiệu quả trong lập trình.
Các thao tác chính bao gồm thêm phần tử (Enqueue), loại bỏ phần tử (Dequeue), xem phần tử ở đầu (Peek), và kiểm tra trạng thái rỗng hoặc đầy. Mỗi thao tác đều tuân thủ nguyên tắc FIFO đã học.
Thao tác Enqueue: Thêm phần tử vào Queue
Thao tác Enqueue được sử dụng để thêm một phần tử mới vào Queue. Theo nguyên tắc FIFO, phần tử mới này luôn được thêm vào cuối (rear) của hàng đợi.
Ví dụ, nếu Queue của bạn đang chứa các phần tử [A, B], khi bạn enqueue phần tử C, Queue sẽ trở thành [A, B, C]. A vẫn ở đầu, C đứng ở cuối.
Việc thêm phần tử vào cuối hàng đợi đảm bảo rằng thứ tự của các phần tử đã có không bị thay đổi. Phần tử mới chỉ đơn giản là chờ đến lượt mình ở vị trí cuối cùng.
Đây là thao tác nhập dữ liệu vào Queue. Nó là bước đầu tiên trong quá trình xử lý tuần tự mà Queue mang lại.
Thao tác Dequeue: Lấy phần tử ra khỏi Queue
Thao tác Dequeue được sử dụng để loại bỏ phần tử ra khỏi Queue. Theo nguyên tắc FIFO, phần tử bị loại bỏ luôn là phần tử đang đứng ở đầu (front) của hàng đợi.
Tiếp tục ví dụ trước, nếu Queue là [A, B, C], khi bạn dequeue, phần tử A sẽ bị loại bỏ. Queue sau đó sẽ trở thành [B, C]. B lúc này trở thành phần tử ở đầu hàng đợi.
Dequeue là thao tác xuất dữ liệu khỏi Queue. Nó mô phỏng việc “phục vụ” hoặc “xử lý” phần tử đã chờ lâu nhất trong hàng đợi.
Cần lưu ý rằng nếu bạn cố gắng dequeue từ một Queue rỗng, đây gọi là trạng thái “underflow” và thường sẽ gây ra lỗi hoặc trả về giá trị đặc biệt (ví dụ: null).
Thao tác Peek (hoặc Front): Xem phần tử ở đầu Queue
Thao tác Peek (hoặc Front) cho phép bạn xem giá trị của phần tử đang đứng ở đầu Queue mà không loại bỏ nó ra khỏi hàng đợi.
Nếu Queue là [B, C], khi bạn gọi thao tác Peek, bạn sẽ nhận được giá trị B. Queue vẫn giữ nguyên là [B, C].
Thao tác này hữu ích khi bạn cần kiểm tra xem phần tử nào sắp được xử lý tiếp theo mà không muốn thay đổi trạng thái của Queue.
Giống như Dequeue, nếu Queue rỗng khi bạn gọi Peek, điều này cũng có thể gây ra lỗi hoặc trả về giá trị đặc biệt.
Kiểm tra trạng thái rỗng và đầy của Queue (isEmpty, isFull)
Các thao tác isEmpty() và isFull() được sử dụng để kiểm tra trạng thái hiện tại của Queue.
isEmpty() trả về true nếu Queue không chứa bất kỳ phần tử nào, và false nếu ngược lại. Thao tác này rất quan trọng để tránh cố gắng dequeue hoặc peek từ một Queue rỗng (gây underflow).
isFull() trả về true nếu Queue đã đạt đến sức chứa tối đa của nó (áp dụng cho các cài đặt Queue có giới hạn kích thước, ví dụ dùng mảng), và false nếu ngược lại. Thao tác này giúp tránh cố gắng enqueue vào một Queue đã đầy (gây overflow).
Các thao tác kiểm tra trạng thái giúp bạn quản lý Queue một cách an toàn và hiệu quả trong các chương trình của mình.
So sánh Queue và Stack: Hai cấu trúc dữ liệu dễ gây nhầm lẫn
Queue và Stack là hai cấu trúc dữ liệu tuyến tính rất cơ bản và thường được giới thiệu cùng nhau. Tuy nhiên, chúng có nguyên tắc hoạt động hoàn toàn khác biệt và đây là điểm dễ gây nhầm lẫn cho người mới học.
Điểm khác biệt cốt lõi nằm ở nguyên tắc xử lý phần tử: Queue là FIFO (First-In, First-Out), còn Stack là LIFO (Last-In, First-Out). Hiểu rõ sự khác biệt này là rất quan trọng.
Trong khi Queue xử lý phần tử theo thứ tự vào trước ra trước (như hàng người), thì Stack xử lý phần tử theo thứ tự vào sau ra trước. Điều này giống như một chồng đĩa: bạn chỉ có thể thêm đĩa mới lên đỉnh và chỉ có thể lấy đĩa ở đỉnh ra. Đĩa được đặt vào sau cùng lại là cái được lấy ra đầu tiên.
- Queue (FIFO): Thêm vào cuối (Enqueue), Lấy ra ở đầu (Dequeue).
- Stack (LIFO): Thêm vào đỉnh (Push), Lấy ra ở đỉnh (Pop).
Mặc dù cả hai đều là cấu trúc dữ liệu tuyến tính và có các thao tác thêm/bớt phần tử, nhưng thứ tự của các thao tác này quyết định chức năng và ứng dụng của chúng. Queue phù hợp cho các tác vụ tuần tự, còn Stack thường dùng cho các tác vụ yêu cầu truy xuất phần tử cuối cùng được thêm vào (ví dụ: theo dõi lời gọi hàm).
Việc phân biệt rõ ràng Queue và Stack sẽ giúp bạn lựa chọn cấu trúc dữ liệu phù hợp cho từng bài toán lập trình cụ thể.
Cài đặt Queue như thế nào trong thực tế?
Trong thực tế, Queue không phải là một kiểu dữ liệu “có sẵn” trong mọi ngôn ngữ lập trình mà thường được xây dựng dựa trên các cấu trúc dữ liệu cơ bản hơn. Hai phương pháp cài đặt Queue phổ biến nhất là sử dụng Mảng (Array) và Danh sách liên kết (Linked List).
Mỗi cách cài đặt có ưu và nhược điểm riêng về hiệu quả bộ nhớ và tốc độ thực hiện các thao tác. Việc lựa chọn phương pháp cài đặt phụ thuộc vào yêu cầu cụ thể của bài toán bạn đang giải quyết.
Cài đặt Queue bằng Mảng (Array)
Cài đặt Queue bằng Mảng sử dụng một mảng cố định hoặc mảng động để lưu trữ các phần tử của Queue. Chúng ta cần sử dụng hai con trỏ (hoặc chỉ số): một con trỏ front để chỉ vị trí đầu Queue và một con trỏ rear để chỉ vị trí cuối Queue.
Khi enqueue, ta thêm phần tử vào vị trí rear và tăng rear lên. Khi dequeue, ta lấy phần tử ở vị trí front và tăng front lên.
Thách thức chính khi dùng mảng là kích thước cố định. Nếu mảng đầy, ta không thể enqueue thêm (overflow). Nếu dequeue nhiều lần, phần tử ở đầu mảng sẽ trống, lãng phí bộ nhớ ở phía trước.
Để khắc phục việc lãng phí bộ nhớ, người ta thường sử dụng Queue vòng (Circular Queue). Trong Queue vòng, khi con trỏ rear hoặc front đạt đến cuối mảng, nó sẽ quay trở lại đầu mảng nếu còn chỗ trống.
Cài đặt bằng mảng có thể hiệu quả về truy cập ngẫu nhiên (nếu cần, dù Queue không thiết kế cho việc này), nhưng quản lý không gian trống và kích thước có thể phức tạp hơn.
Cài đặt Queue bằng Danh sách liên kết (Linked List)
Cài đặt Queue bằng Danh sách liên kết sử dụng các nút (node) được liên kết với nhau, mỗi nút chứa một phần tử dữ liệu và con trỏ đến nút tiếp theo. Chúng ta cần giữ con trỏ đến nút đầu tiên (front) và nút cuối cùng (rear) của danh sách.
Khi enqueue, ta tạo một nút mới và thêm nó vào cuối danh sách liên kết, cập nhật con trỏ rear. Khi dequeue, ta lấy nút đầu tiên ra khỏi danh sách và cập nhật con trỏ front.
Phương pháp này linh hoạt hơn mảng vì kích thước của Queue có thể tăng hoặc giảm động theo số lượng phần tử. Không có vấn đề về overflow (trừ khi hết bộ nhớ hệ thống) hoặc lãng phí không gian trống cố định.
Tuy nhiên, việc cài đặt bằng danh sách liên kết có thể tốn thêm bộ nhớ cho các con trỏ trong mỗi nút so với cài đặt bằng mảng (đặc biệt với các phần tử nhỏ). Nhưng nhìn chung, đây là cách cài đặt Queue phổ biến và hiệu quả trong nhiều trường hợp.
Ứng dụng phổ biến của Queue trong Công nghệ thông tin
Queue không chỉ là một khái niệm lý thuyết mà còn được ứng dụng rộng rãi trong rất nhiều lĩnh vực của Công nghệ thông tin. Nguyên tắc FIFO của nó giải quyết hiệu quả nhiều bài toán cần xử lý các yêu cầu hoặc dữ liệu theo thứ tự thời gian đến.
Hiểu các ứng dụng này giúp bạn thấy được tầm quan trọng và tính thực tế của cấu trúc dữ liệu Queue.
Quản lý tác vụ/tiến trình trong Hệ điều hành
Queue được sử dụng rộng rãi trong các hệ điều hành để quản lý hàng đợi các tác vụ hoặc tiến trình đang chờ được thực thi bởi CPU. Khi nhiều chương trình yêu cầu tài nguyên CPU cùng lúc, chúng sẽ được xếp vào một hàng đợi.
Hệ điều hành sẽ lấy từng tiến trình ra khỏi hàng đợi (theo nguyên tắc FIFO hoặc các biến thể phức tạp hơn của Queue như Priority Queue) để cấp phát thời gian xử lý. Điều này đảm bảo các tiến trình được xử lý một cách công bằng theo thứ tự yêu cầu.
Các hàng đợi khác cũng tồn tại trong hệ điều hành, ví dụ hàng đợi cho các yêu cầu nhập/xuất (I/O) đến ổ đĩa hoặc thiết bị khác.
Sử dụng trong các thuật toán (Ví dụ: BFS)
Một ứng dụng quan trọng của Queue trong lĩnh vực giải thuật là thuật toán Tìm kiếm theo chiều rộng (BFS - Breadth-First Search) trên đồ thị hoặc cây. BFS dùng Queue để khám phá các đỉnh (node) của đồ thị theo từng “lớp” hoặc “mức”.
Khi thăm một đỉnh, thuật toán sẽ thêm tất cả các đỉnh kề chưa được thăm vào Queue. Sau đó, nó sẽ lấy các đỉnh từ đầu Queue ra để thăm tiếp, đảm bảo rằng tất cả các đỉnh ở mức hiện tại được thăm trước khi chuyển sang mức tiếp theo.
Việc sử dụng Queue đảm bảo rằng thuật toán BFS luôn tìm thấy đường đi ngắn nhất (tính theo số cạnh) từ đỉnh nguồn đến các đỉnh khác trong đồ thị không trọng số.
Bộ đệm (Buffer) trong truyền dữ liệu
Queue thường được sử dụng làm bộ đệm (buffer) để xử lý dữ liệu được truyền không đồng bộ giữa hai hệ thống hoặc quá trình có tốc độ khác nhau. Dữ liệu được đưa vào buffer (enqueue) bởi bên sản xuất dữ liệu (producer) và được lấy ra khỏi buffer (dequeue) bởi bên tiêu thụ dữ liệu (consumer).
Ví dụ, khi tải video trực tuyến, dữ liệu video được tải về và lưu vào buffer (Queue) trước khi được phát cho người xem. Nếu tốc độ tải về nhanh hơn tốc độ phát, buffer sẽ đầy dần. Nếu tốc độ phát nhanh hơn tốc độ tải về, buffer sẽ cạn dần, có thể gây giật lag.
Bộ đệm giúp làm mượt quá trình xử lý dữ liệu khi tốc độ giữa các thành phần không đồng nhất.
Hàng đợi yêu cầu (Ví dụ: máy in, server)
Trong môi trường mạng hoặc chia sẻ tài nguyên, Queue được dùng để quản lý hàng đợi các yêu cầu từ nhiều người dùng hoặc thiết bị khác nhau đến một tài nguyên duy nhất.
Ví dụ điển hình là hàng đợi máy in: khi nhiều người gửi lệnh in cùng lúc, các lệnh này sẽ được xếp hàng và máy in sẽ xử lý từng lệnh một theo thứ tự (FIFO).
Tương tự, các server web hoặc cơ sở dữ liệu sử dụng Queue để quản lý hàng đợi các yêu cầu từ client. Điều này giúp server xử lý từng yêu cầu một cách có tổ chức và ngăn chặn tình trạng quá tải.
Các biến thể của Queue (Priority Queue, Deque…)
Ngoài cấu trúc Queue cơ bản tuân thủ nghiêm ngặt FIFO, còn có một số biến thể nâng cao hơn được sử dụng trong các tình huống đặc biệt.
Priority Queue (Hàng đợi ưu tiên) là một biến thể quan trọng. Trong cấu trúc này, mỗi phần tử có một “ưu tiên” đi kèm. Khi dequeue, phần tử có độ ưu tiên cao nhất sẽ được lấy ra trước, bất kể thời gian nó được enqueue. Nếu hai phần tử có cùng ưu tiên, thứ tự FIFO có thể được áp dụng.
Deque (Double-ended queue), viết tắt của “Double-ended queue”, là một hàng đợi cho phép thêm và xóa phần tử ở cả hai đầu (front và rear). Deque linh hoạt hơn Queue và Stack cơ bản, có thể hoạt động như cả hai cấu trúc tùy thuộc vào cách sử dụng.
Việc tìm hiểu về các biến thể này sẽ mở rộng hiểu biết của bạn về cách nguyên tắc hàng đợi có thể được điều chỉnh để phù hợp với các yêu cầu phức tạp hơn trong thực tế.
Kết luận
Queue là một cấu trúc dữ liệu fundamental (cơ bản) trong khoa học máy tính, tuân thủ nguyên tắc FIFO (First-In, First-Out). Nó hoạt động như một hàng đợi trong đời sống thực, nơi phần tử vào trước sẽ ra trước.
Chúng ta đã cùng nhau tìm hiểu định nghĩa của Queue, nguyên lý FIFO, các thao tác cơ bản như enqueue (thêm vào cuối), dequeue (lấy ra ở đầu), peek (xem đầu), và kiểm tra trạng thái. Chúng ta cũng đã so sánh sự khác biệt rõ rệt giữa Queue và Stack (LIFO).
Bài viết cũng đã chỉ ra rằng Queue có thể được cài đặt hiệu quả bằng Mảng hoặc Danh sách liên kết, mỗi cách có ưu nhược điểm riêng. Quan trọng nhất, chúng ta đã thấy Queue xuất hiện ở khắp mọi nơi trong thế giới công nghệ, từ quản lý tiến trình trong Hệ điều hành, các thuật toán như BFS, đến làm bộ đệm và quản lý hàng đợi yêu cầu.
DỊCH VỤ LIÊN QUAN
Để biến kiến thức về cấu trúc dữ liệu hay giải thuật thành sản phẩm thực tế, bạn cần nền tảng hạ tầng đáng tin cậy. Với dịch vụ thuê Hosting giá rẻ (1K/Ngày) chất lượng uy tín, việc đưa website online trở nên đơn giản. Khi dự án lớn mạnh hơn, dịch vụ thuê VPS giá rẻ (3K/Ngày) uy tín tốc độ cao với bộ xử lý AMD EPYC Gen 3th và SSD NVMe U.2 mang đến hiệu năng ấn tượng.
Đối với các ứng dụng đòi hỏi tài nguyên lớn và khả năng mở rộng linh hoạt, dịch vụ thuê Cloud Server (5K/Ngày) chất lượng giá rẻ cấu hình cao là giải pháp tối ưu. Nền tảng này sử dụng phần cứng chuyên dụng thế hệ mới, công nghệ ảo hóa tiên tiến cung cấp băng thông cao và dung lượng được tối ưu. Điều này giúp đảm bảo tốc độ và sự ổn định cho mọi workload phức tạp.