Installation
pip install selenium
pip install beautifulsoup4
pip install requests
Page Scraping
For demo, we will scrape books.toscrape.com, a fiction book store. Its pages are not dynamic, or static, however, its functionality might be similar.
import pandas as pd from selenium import webdriver from bs4 import BeautifulSoup import re import requests import time url = 'https://books.toscrape.com/catalogue/page-1.html' driver = webdriver.Chrome() driver.implicitly_wait(30) driver.get(url) soup = BeautifulSoup(driver.page_source,'lxml') driver.quit()
The beyond might load the URL within a Chrome browser as well as wait for elements to load, pass the page resources to BeautifulSoup as welll as end a browser session. For the pages, which take long time for loading, you might need to mess around with waiting time (in seconds).
Our soup looks like this. It’s time to start scraping useful elements!

Scraping Elements
To get an element, we could filter through its tag names or attribute name as well as attribute value.
For scraping all product names at the initial page of the fictional book store, let’s recognize which elements they got stored in. This looks like the text is reliably stored in
tag.

soup.find() get the initial element, which matches with our filter: the tag name matches ‘h3’.

Adding .string returns the element texts only.

soup.find_all() gets all the elements, which match with our filter as well as returns them within the list. Note: soup.find_all() as well as soup() would function similar in cse, you’re a brevity fan.

Finally, looping through.string in the list comprehension returns the elements’ texts. Now, we have got the list of 20 products’ names!
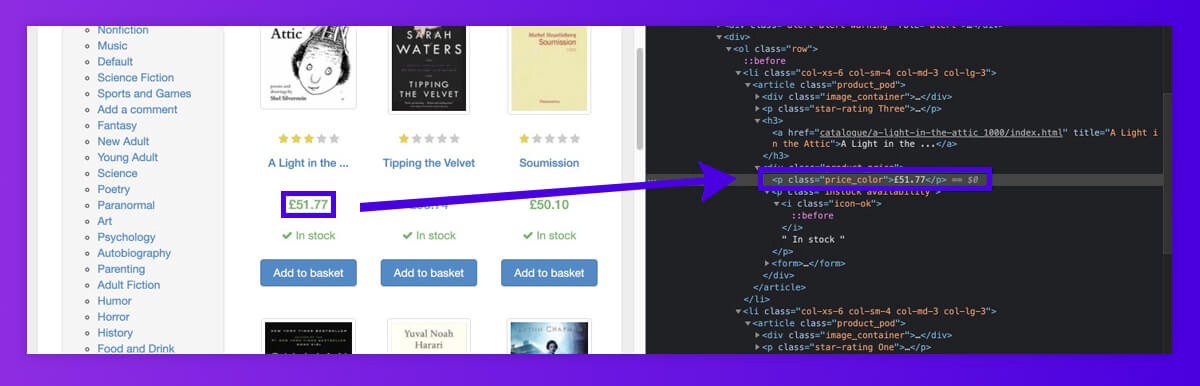
The similar can be made with all the product details. To find all product prices, we have filtered through attribute name called ‘class’ as well as attribute value called ‘price_color’.

You can stop here as wella s focus on lists of various product details and it might work very well for the websites having clean HTML. However, e-commerce websites are not always clear as well as troubleshooting for the exceptions could be the most time-consuming part of the procedure.
Missing Elements
It is the most general exception we have encountered.
What occurs when elements are lost for certain products? For instance, if any product is provisionally unavailable as well as there are no tags having prices for the product. Rather than having null values in a list, we might get the price list, which is shorter than list of different product names as well as run risks of getting incorrect pricing against the products.
To avoid that, we found it best for first filtering to the outer elements, which contain all the product data then within every outer element get particular inner elements like product’s name, pricing, etc. We could include the condition for returning the null value in case, the inner elements are missing from the product tiles. It will make sure all the product data is in same order within our lists.


[Return null value if inner element is missing else return text of inner element for x in all outer elements]
Put that all together in the Pandas DataFrame
df = pd.DataFrame(list(zip([None if x == None else x.string for x in soup.find_all('h3')], [None if x.find(attrs={'class':'price_color'}) == None else x.find(attrs={'class':'price_color'}).string.replace('£','') for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})], [None if x.find(attrs={'class':'instock availability'}).text == None else x.find(attrs={'class':'instock availability'}).text.strip() for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})], [None if x.find(attrs={'class':re.compile(r'star-rating$')}).get('class') == None else x.find(attrs={'class':re.compile(r'star-rating$')}).get('class')[1] for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})])), columns=['product_name','price','availability','rating'])
We may put the lists of various product data straight in the Pandas DataFrame as well as name every column.
For all ways, you can more navigate the elements, see a BeautifulSoup documentation.
It is also a very good time for preprocessing some features including removing the currency symbols as well as removing the whitespaces around the text.
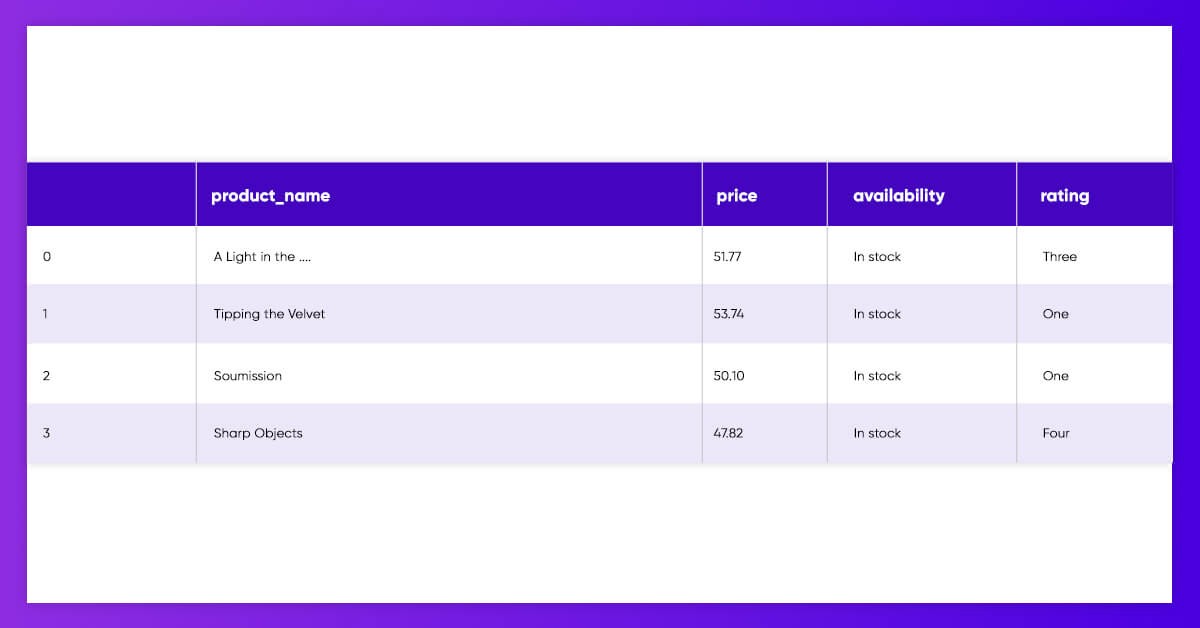
To get it easily done, we may put that in the function to scrape the page having a single line of code.
def scrape_page(url): driver = webdriver.Chrome() driver.implicitly_wait(30) driver.get(url) soup = BeautifulSoup(driver.page_source,'lxml') driver.quit() df = pd.DataFrame(list(zip([None if x == None else x.string for x in soup.find_all('h3')], [None if x.find(attrs={'class':'price_color'}) == None else x.find(attrs={'class':'price_color'}).string.replace('£','') for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})], [None if x.find(attrs={'class':'instock availability'}).text == None else x.find(attrs={'class':'instock availability'}).text.strip() for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})], [None if x.find(attrs={'class':re.compile(r'star-rating$')}).get('class') == None else x.find(attrs={'class':re.compile(r'star-rating$')}).get('class')[1] for x in soup.find_all(attrs={'class':'col-xs-6 col-sm-4 col-md-3 col-lg-3'})])), columns=['product_name','price','availability','rating']) return df scrape_page('https://books.toscrape.com/catalogue/page-1.html')
Pagination
For scraping products, which span across different pages, we could put that in the function, which iterates through every page’s url. This appends DataFrames from all the extracted pages.
def scrape_multiple_pages(url,pages): #Input parameters of url and number of pages to scrape. Put {} in place of page number in url. page_number = list(range(pages)) df = pd.DataFrame(columns=['product_name','price','availability','rating']) for i in range(len(page_number)): #Loops through each page number in url. if requests.get(url.format(i+1)).status_code == 200: #If the url returns an OK 200 reponse, scrape the page. df_page = scrape_page(url.format(i+1)) df = df.append(df_page) time.sleep(5) #Wait 5 seconds. else: break return df scrape_multiple_pages('https://books.toscrape.com/catalogue/page-{}.html',pages=2)
In this URL parameter, we dynamically populate page numbers using {} as well as .format(). The pages parameters define the maximum number of pages for scraping, beginning at 1.
We have also added extra steps to run if the URL returns the OK 200 reply as well as sleep for merely 5 seconds between the pages.
Conclusion
Here are some things to think about:
It’s very important to consider about how much you extract as extra server calls could easily add.
You should consider that as we require to load as well as run Javascript for all pages, this technique is slower for all programmatic standards as well as not much scaleable.
With any extracting, element scraping needs to get tailored for all sites as HTML structures would differ across websites.
However, for scraping come pages at one time, it is a very easy and helpful solution, which only utilizes some code lines.