In this tutorial I will explain how to extract structured data from a search engine by writing a simple python script and using the selenium library. If you don’t have the selenium library you can install it by following my practical tutorial: https://www.youtube.com/watch?v=mHtlBq5cP2Y.
You can also download the code written in this tutorial from my github repository: GitHub - alod83/python-samples: This repository contains python samples
6 steps
Six steps are needed to write a good scraper for a search engine:
- Open the page of the search engine
- Accept cookies
- Write a keyword on the search bar
- Wait for results
- Parse all the pages of results
- Save results into a CSV file
In this tutorial we will extract structured information from the web site: https://www.paginebianche.it/
Open the page
In order to open the page, you should import the selenium library and call the Chrome() class:
from selenium import webdriver
driver = webdriver.Chrome()
page = driver.get(“https://www.paginebianche.it/")
Accept cookies
Cookies should be accepted in all the cases when writing a scraper. In order to accept a cookie in the script, firstly we should identify it. Manually open the page of the search engine and select the button corresponding to the cookie with the right button of the mouse. From the menu, we select Inspect and a new page opens.

The new page contains the html code of the page and highlights the part associated to the button:
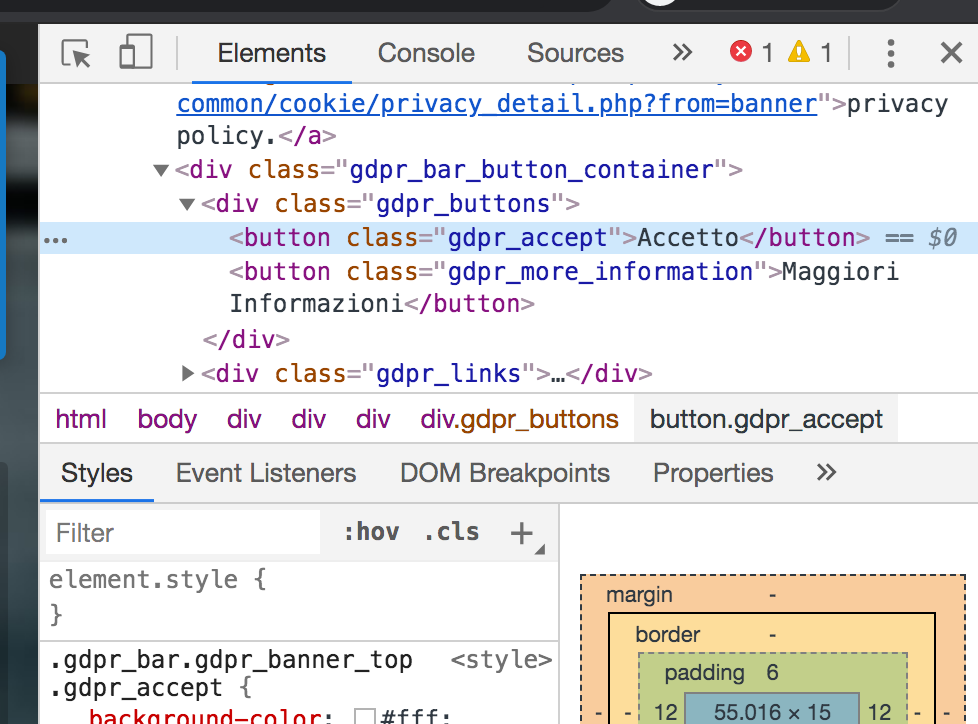
We note that the button associated to cookies corresponds to the class “gdpr_accept”, which corresponds to the relative xpath: //*[@class=’gdpr_accept’]. You can also extract the absolute xpath by selecting the button on the html code and right clicking it. You can now select Copy → Copy full Xpath: /html/body/div[9]/div/div/div[1]/button[1]

Now you can write the code corresponding to the accept cookies operation. Firstly you select the button and then you click on it:
cookies = driver.find_element_by_xpath(“//*[@class=’gdpr_accept’]”)
cookies.click()
Write a keyword on the search bar
Now we apply the same mechanism used for cookies to select the search bar. We right click on the search bar in order to extract the xpath and we select the inspect option:
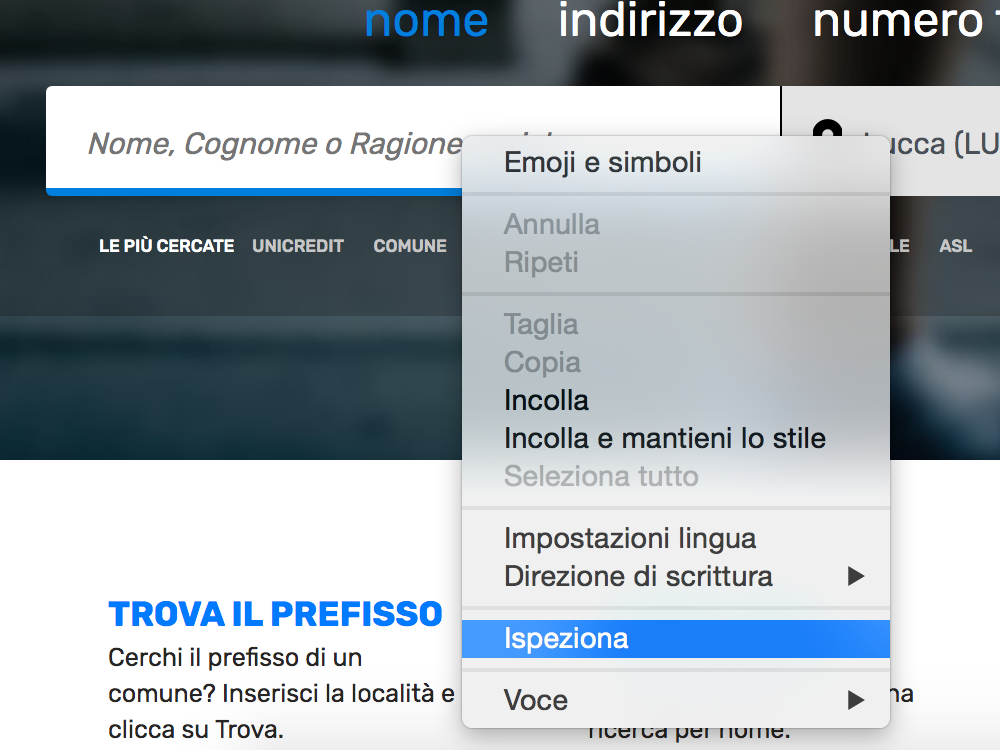
We get the html tag and the corresponding xpath: //*[@id=”frmName”]/div[1]/input

Now we can write the code, for example by searching for hotels:
activity = “hotel”
search_activity = driver.find_element_by_xpath(“//*[@id=’frmName’]/div[1]/input”)
search_activity.send_keys(activity)
We use the function send_keys to send an input value to the search bar. In our case we search for the keyword “hotel”. We do the same operation with the search bar associated to the city. We copy the xpath, we select the element and we send the input keyword “Pisa”:
place = “Pisa”
search_place = driver.find_element_by_xpath(“//*[@id=’input_dove’]”)
search_place.send_keys(place)
Now we can submit results by sending the submit command to the submit button:
search = driver.find_element_by_xpath(“//*[@id=’frmNameSubmit’]”)
search.submit()
Wait for results
Now we have to wait for results. This can be done by invoking the sleep function, included in the time library. For example we can wait for 5 seconds.
import time
time.sleep(5)
Parse all the pages of results
Eventually results are shown in the page, like in the following figure:
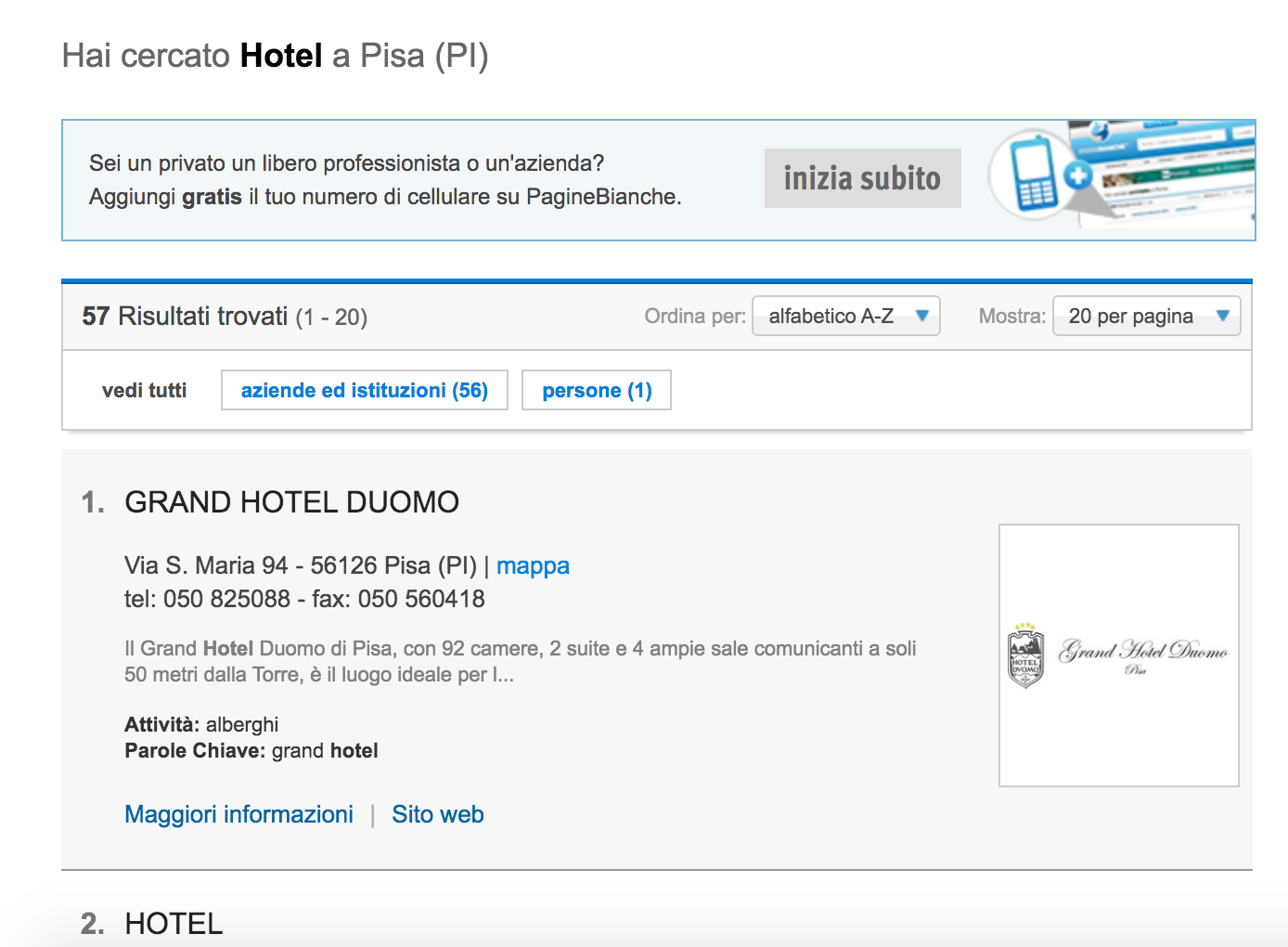
Results are paginated and, as shown in the figure, each page shows 20 items. Thus we have to retrieve information about 20 item by doing a loop from 1 to 20. For each item we extract name, postal code, city, address, telephone and fax. The method is always the same: copy the xpath of each html tag and get the value. It may happen that some information is missing so we can manage this case using the try-except block which manages for exceptions. Each item is identified by a progressive number from 1 to 20 so we can use an index i which selects the i-th element. We store all the extracted information into a dictionary called hotel.
hotel = {}
i = 1try:
hotel[‘name’] = driver.find_element_by_xpath(“//[@id=’co_” +
str(i) + “‘]/div[1]/div[1]/div/h2/a”).text
except:
breakhotel[‘address’] = driver.find_element_by_xpath(“//[@id=’co_” + str(i) + “‘]/div[1]/div[2]/div[1]/div/span/span[1]”).texthotel[‘postal_code’] = driver.find_element_by_xpath(“//[@id=’co_” + str(i) + “‘]/div[1]/div[2]/div[1]/div/span/span[2]”).texthotel[‘locality’] = driver.find_element_by_xpath(“//[@id=’co_” + str(i) + “‘]/div[1]/div[2]/div[1]/div/span/span[2]”).texttry:
hotel[‘telephone’] = driver.find_element_by_xpath(“//[@id=’co_” + str(i) + “‘]/div[1]/div[2]/div[3]/div/span[2]”).text
except:
hotel[‘telephone’] = ‘’try:
hotel[‘fax’] = driver.find_element_by_xpath(“//[@id=’co_” + str(i) + “‘]/div[1]/div[2]/div[3]/div/span[4]”).text
except:
hotel[‘fax’] = ‘’
The search engine provides also the latitude and the longitude of every item. However, they are contained into some hidden fields, thus they cannot be retrieved through the xpath. Thus we have to access the html tag by running a javascript command.
In order to find in which html tag latitude and longitude are located, we can open the html inspector, by right clicking in a generic part of the html page and search for the word “latitude”. We can open the finding window by typing CMD+F or Ctrl+F:
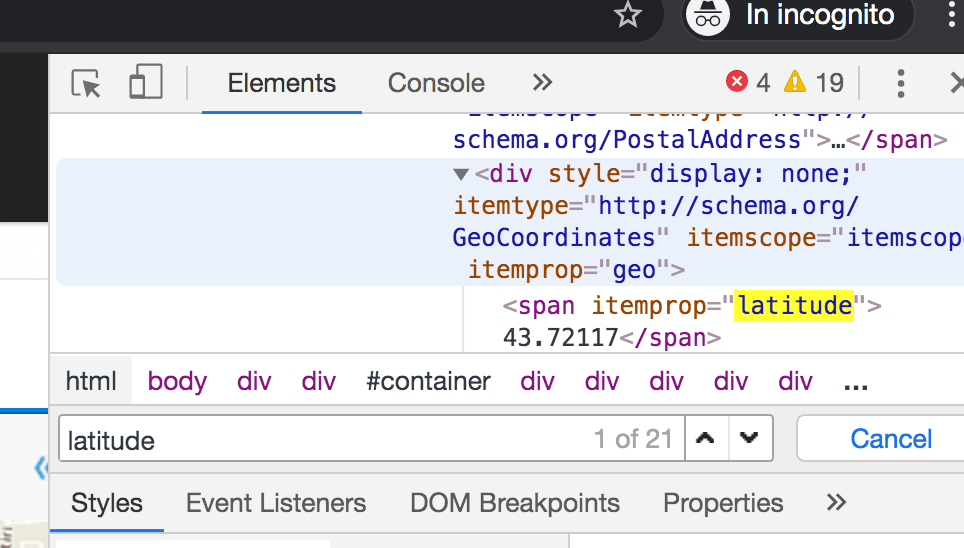
Once found where the latitude tag is, we can right click with the mouse and select copy the JS path: document.querySelector(“#addr_1 > div > div > span:nth-child(1)”). Now we can run a JS script within our python script and return the textContent associated to the previous path:
hotel[‘latitude’] = driver.execute_script(“return document.querySelector(‘#addr_” + str(i) + “ > div > div > span:nth-child(1)’).textContent;”)
The same procedure can be used for longitude:
hotel[‘longitude’] = driver.execute_script(“return document.querySelector(‘#addr_” + str(i) + “ > div > div > span:nth-child(2)’).textContent;”)
All the retrieved information up to now are related to a single item. We have to repeat the written code for all the items in the page:
hotels =
n = 21for i in range(1,n):
retrieve information for each item (copy the code above)
hotels.append(hotel)
We create a list hotels, which will contain all the hotels and then we run a loop from 1 to n-1. This code works for a single page. We have to generalize it to all the pages. In advance we do not know the number of pages, so we create an infinite loop which will end when a particular condition happens. Firstly we identify the next page button through the previous described method and then we click on it:
next_page = driver.find_element_by_xpath(“//*[@id=’container’]/div[2]/div/div/div[4]/div[2]/div[22]/div/div/ul/li[4]/a”)
next_page.click()
When there are no more pages the search of this last element will raise an exception which can be used to exit the infinite loop:
while True:
for i in range(1,n):
get hotel information
try:
next_page = driver.find_element_by_xpath(“//* [@id=’container’]/div[2]/div/div/div[4]/div[2]/div[22]/div/div/ul/li[4]/a”) next_page.click()
except:
break
Save results into a CSV file
All the results are stored in the hotels variable, so it is sufficient to save it on a CSV file. From the first element of the list we get the keys which well be used as header of the CSV:
import csvkeys = hotels[0].keys()with open(‘hotels.csv’, ‘w’) as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(hotels)