Hash table (hay bảng băm) là một trong những cấu trúc dữ liệu mạnh mẽ và được sử dụng phổ biến nhất trong khoa học máy tính và lập trình. Nó cho phép lưu trữ và truy xuất dữ liệu cực nhanh dựa trên các cặp khóa-giá trị. Bài viết này sẽ đi sâu giải thích Hash table là gì, cách nó hoạt động, ưu nhược điểm, và ứng dụng thực tế, giúp bạn nắm vững kiến thức nền tảng này.
VPS GIÁ RẺ UY TÍN - CẤU HÌNH AMD - FULL NVME
Triển khai các ứng dụng tận dụng sức mạnh của Hash table đòi hỏi một môi trường máy chủ ổn định. Nếu bạn cần một nền tảng đáng tin cậy để đưa các dự án lập trình của mình vào thực tế, thuê VPS giá rẻ tại InterData cung cấp cấu hình mạnh mẽ với bộ xử lý AMD EPYC Gen 3, SSD NVMe U.2 tốc độ cao, băng thông lớn, giá chỉ từ 3K/Ngày, mang đến hiệu năng cao, chất lượng và uy tín.
Hash table là gì?
Hash table (hay bảng băm) là một cấu trúc dữ liệu mạnh mẽ, cho phép bạn lưu trữ thông tin dưới dạng các cặp khóa và giá trị (key-value pairs). Mục đích chính của nó là giúp truy xuất dữ liệu cực kỳ nhanh chóng, thường chỉ trong một bước.

Ưu điểm nổi bật nhất của Hash table chính là tốc độ tìm kiếm, chèn và xóa dữ liệu. Trung bình, các thao tác này có thể thực hiện chỉ trong thời gian không đổi O(1), làm cho nó rất hiệu quả với lượng dữ liệu lớn.
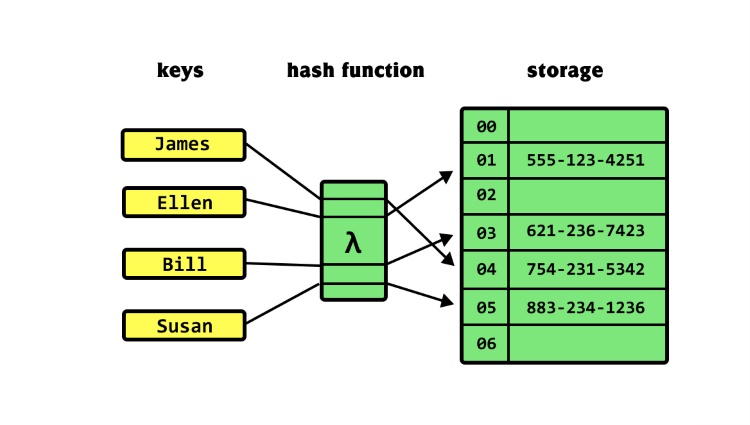
Tương tự như một cuốn từ điển hoặc danh bạ điện thoại, mỗi mẩu thông tin trong Hash table được liên kết với một “khóa” (key) duy nhất. Bạn sử dụng khóa này để nhanh chóng tìm ra “giá trị” (value) tương ứng mà bạn muốn truy cập.
Để đạt được tốc độ cao, Hash table dựa vào một thành phần quan trọng gọi là hàm băm (hash function). Hàm này đóng vai trò như một công cụ “biến đổi”, nhận đầu vào là khóa (key) của bạn và biến đổi nó thành một con số.
Con số mà hàm băm tạo ra thường được sử dụng như một chỉ mục (index) hoặc địa chỉ trong một cấu trúc mảng (array) bên dưới. Đây chính là vị trí mà cặp key-value tương ứng sẽ được lưu trữ hoặc truy xuất đến một cách trực tiếp.
Về cơ bản, Hash table được xây dựng trên một cấu trúc nền là mảng (array), chứa các “ngăn” hoặc “vị trí” lưu trữ gọi là bucket (hoặc slot). Chỉ mục từ hàm băm giúp xác định chính xác bucket nào sẽ chứa dữ liệu của khóa đó.
Một thách thức phổ biến trong Hash table là đụng độ (collision). Tình huống này xảy ra khi hàm băm tạo ra cùng một chỉ mục cho hai hoặc nhiều khóa (key) khác nhau, dẫn đến việc nhiều mục dữ liệu muốn được lưu cùng một chỗ.
Khi đụng độ xảy ra, Hash table cần có các phương pháp đặc biệt để “giải quyết” tình huống này, đảm bảo không có dữ liệu nào bị mất và tất cả các cặp key-value vẫn có thể được tìm thấy chính xác sau đó.
Nhờ cơ chế băm và ánh xạ trực tiếp từ khóa (key) sang vị trí lưu trữ (index), Hash table cho phép truy cập dữ liệu với hiệu năng vượt trội. Điều này lý giải tại sao nó cực kỳ hiệu quả cho các thao tác tìm kiếm nhanh trên tập dữ liệu lớn.
Trong nhiều ngôn ngữ lập trình phổ biến, các cấu trúc dữ liệu quen thuộc như Dictionary (trong Python), HashMap (trong Java) hay unordered_map (trong C++) thường được cài đặt dựa trên nền tảng Hash table để đạt được hiệu suất cao nhất cho việc tìm kiếm nhanh.
Hash table hoạt động như thế nào?
Cơ chế hoạt động cốt lõi của Hash table xoay quanh việc biến đổi khóa (key) thành một địa chỉ cụ thể trong bộ nhớ. Điều này được thực hiện nhờ sự kết hợp của hàm băm và một mảng các bucket.
Khi bạn muốn chèn một cặp key-value mới vào Hash table, hệ thống sẽ lấy khóa (key) và đưa nó vào hàm băm. Hàm băm sẽ xử lý khóa này và trả về một giá trị số nguyên.
Giá trị số nguyên này sau đó được sử dụng để tính toán chỉ mục (index) tương ứng trong mảng các bucket. Thông thường, phép toán modulo (%) được áp dụng với kích thước của mảng để đảm bảo chỉ mục nằm trong giới hạn hợp lệ.
Kết quả cuối cùng là một chỉ mục trỏ đến một vị trí (bucket) cụ thể trong Hash table. Cặp key-value ban đầu sẽ được lưu trữ tại bucket được xác định bởi chỉ mục này.
Khi bạn muốn tìm kiếm một giá trị dựa trên khóa của nó, quy trình tương tự cũng diễn ra. Khóa tìm kiếm được đưa vào cùng hàm băm đó để tạo ra chỉ mục.
Chỉ mục này sẽ dẫn bạn trực tiếp đến bucket được cho là chứa cặp key-value bạn cần. Lúc này, hệ thống chỉ cần kiểm tra nội dung bên trong bucket đó để tìm ra giá trị mong muốn.
Vai trò của Hàm băm (Hash Function)
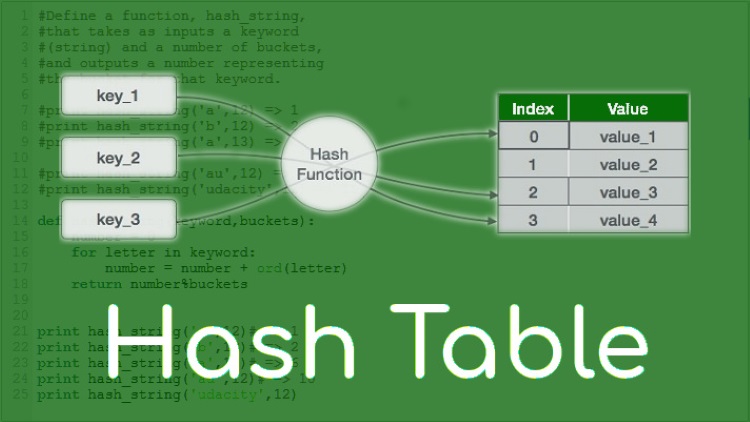
Hàm băm (Hash Function) là trung tâm hoạt động của Hash table. Nó là một thuật toán nhận đầu vào là dữ liệu có kích thước bất kỳ (khóa - key) và tạo ra đầu ra là một chuỗi ký tự hoặc số có kích thước cố định (giá trị băm - hash value).
Trong bối cảnh Hash table, giá trị băm (hash value) sau khi được xử lý (thường là lấy modulo) sẽ trở thành chỉ mục (index) để truy cập mảng các bucket. Hàm băm tốt sẽ phân phối các khóa đều khắp các bucket.
Một hàm băm tốt cần có tính chất xác định (deterministic): cùng một đầu vào (khóa) phải luôn tạo ra cùng một đầu ra (giá trị băm). Điều này đảm bảo khi bạn tìm kiếm một khóa, nó luôn được ánh xạ đến cùng một bucket nơi nó đã được lưu trữ.
Chất lượng của hàm băm ảnh hưởng trực tiếp đến hiệu suất của Hash table. Hàm băm kém có thể tạo ra nhiều đụng độ, làm giảm tốc độ truy xuất dữ liệu đáng kể, thậm chí biến thao tác O(1) lý thuyết thành O(n) trong trường hợp xấu nhất.
Quá trình ánh xạ (Mapping)
Quá trình ánh xạ (Mapping) là bước chuyển đổi giá trị số nguyên từ hàm băm thành chỉ mục hợp lệ của mảng chứa các bucket. Bước này đảm bảo rằng chỉ mục luôn nằm trong phạm vi từ 0 đến kích thước mảng trừ 1.
Thông thường, phép toán modulo (%) được sử dụng để thực hiện ánh xạ. Chỉ mục cuối cùng sẽ là index = hash_value % array_size. Ví dụ, nếu hàm băm trả về 12345 và kích thước mảng là 100, chỉ mục sẽ là 12345 % 100 = 45.
Nhờ quá trình ánh xạ này, mỗi khóa đều được “dẫn lối” đến một bucket cụ thể trong mảng. Đây là bước quyết định cho khả năng truy cập “ngẫu nhiên” hoặc “trực tiếp” vào dữ liệu, nền tảng cho tốc độ O(1).
Quá trình mapping cần đơn giản và hiệu quả để không làm chậm đáng kể hiệu suất tổng thể của thao tác băm. Nó hoạt động song song với hàm băm để xác định chính xác vị trí lưu trữ.
Lưu trữ dữ liệu trong Bucket (hoặc Slot)
Bucket (hay còn gọi là slot, ngăn) là các vị trí lưu trữ thực tế dữ liệu trong Hash table. Về cơ bản, Hash table là một mảng (array) và mỗi phần tử của mảng chính là một bucket.
Mỗi bucket có thể lưu trữ một hoặc nhiều cặp key-value, tùy thuộc vào phương pháp xử lý đụng độ được sử dụng. Ban đầu, khi Hash table trống, tất cả các bucket đều rỗng.
Khi một cặp key-value được băm và ánh xạ tới một chỉ mục, nó sẽ được đưa vào bucket tương ứng với chỉ mục đó. Nếu bucket đã có dữ liệu, đây là lúc xảy ra đụng độ và cần cơ chế xử lý.
Bucket có thể được triển khai bằng nhiều cách khác nhau. Cách phổ biến nhất là sử dụng danh sách liên kết (linked list) hoặc một mảng nhỏ (array) để lưu trữ các phần tử bị đụng độ tại cùng một chỉ mục.
Các thành phần chính của Hash table
Để hiểu rõ hơn về Hash table, việc nhận diện các thành phần cấu tạo nên nó là rất quan trọng. Mỗi thành phần đóng một vai trò cụ thể trong quá trình lưu trữ và truy xuất dữ liệu hiệu quả.
Khóa (Key): Là thành phần dùng để nhận diện và truy xuất dữ liệu. Mỗi khóa phải là duy nhất trong Hash table. Khóa được dùng làm đầu vào cho hàm băm.
Giá trị (Value): Là dữ liệu thực tế bạn muốn lưu trữ, liên kết với một Khóa cụ thể. Value có thể là bất kỳ loại dữ liệu nào (số, chuỗi, đối tượng…).
Hàm băm (Hash Function): Là thuật toán biến đổi Khóa thành một giá trị số nguyên. Giá trị này được dùng để tính toán chỉ mục của Bucket.
Bucket (hoặc Slot): Là các vị trí lưu trữ trong Hash table, được tổ chức như một mảng. Mỗi Bucket có thể chứa một hoặc nhiều cặp Key-Value.
Đụng độ (Collision) trong Hash table và cách xử lý
Đụng độ là vấn đề phổ biến trong Hash table và cần được giải quyết hiệu quả để duy trì hiệu suất. Nó xảy ra khi hai hoặc nhiều khóa khác nhau lại băm ra cùng một chỉ mục trong mảng bucket.
Nếu không có cơ chế xử lý đụng độ, dữ liệu mới có thể ghi đè lên dữ liệu cũ tại cùng một bucket, dẫn đến mất mát thông tin. Do đó, việc xử lý đụng độ là một phần không thể thiếu khi thiết kế hoặc sử dụng Hash table.
Tại sao đụng độ lại xảy ra?
Nguyên nhân chính khiến đụng độ xảy ra là vì không gian của các khóa tiềm năng (ví dụ: tất cả các chuỗi ký tự có thể có) thường lớn hơn rất nhiều so với số lượng bucket có sẵn trong Hash table.
Hàm băm cố gắng phân phối các khóa này vào một không gian địa chỉ (chỉ mục bucket) nhỏ hơn. Theo nguyên lý chuồng bồ câu, nếu có nhiều “bồ câu” (khóa) hơn “chuồng” (bucket), chắc chắn sẽ có ít nhất một chuồng chứa nhiều hơn một bồ câu.
Thêm vào đó, hàm băm không hoàn hảo cũng là một yếu tố. Một hàm băm không tốt có thể tập trung nhiều khóa vào một vài bucket nhất định thay vì phân tán đều, làm tăng đáng kể khả năng đụng độ.
Việc Hash table đầy dần cũng làm tăng khả năng đụng độ. Khi tỉ lệ tải (load factor - số lượng phần tử / số lượng bucket) tăng lên, xác suất để một khóa mới băm vào một bucket đã có dữ liệu sẽ cao hơn.
Các phương pháp xử lý đụng độ phổ biến
Có hai phương pháp chính để xử lý đụng độ trong Hash table: Kết nối riêng biệt (Separate Chaining) và Địa chỉ mở (Open Addressing).
1. Separate Chaining (Kết nối riêng biệt):
Phương pháp này giải quyết đụng độ bằng cách làm cho mỗi bucket trong mảng chính chứa một cấu trúc dữ liệu khác, thường là một danh sách liên kết (Linked List) hoặc một mảng động nhỏ.
Khi nhiều khóa băm vào cùng một chỉ mục, tất cả các cặp key-value tương ứng sẽ được thêm vào danh sách hoặc mảng tại bucket đó.
Để tìm kiếm, chèn hoặc xóa một phần tử khi sử dụng Separate Chaining, trước tiên bạn băm khóa để tìm đúng bucket. Sau đó, bạn thực hiện thao tác (tìm kiếm, chèn, xóa) trên danh sách liên kết hoặc mảng tại bucket đó.
Ưu điểm của phương pháp này là đơn giản để triển khai và không yêu cầu Hash table phải có nhiều chỗ trống. Nhược điểm là tốn thêm bộ nhớ cho các cấu trúc dữ liệu phụ (Linked List Node) và thao tác trên danh sách có thể chậm hơn O(1) nếu danh sách quá dài.
2. Open Addressing (Địa chỉ mở):
Khác với Separate Chaining, Open Addressing lưu trữ tất cả các cặp key-value trực tiếp trong mảng các bucket chính. Khi đụng độ xảy ra, hệ thống sẽ tìm một bucket trống khác trong mảng để lưu trữ dữ liệu mới.
Quá trình tìm kiếm một bucket thay thế khi đụng độ được gọi là “thăm dò” (probing). Có nhiều chiến lược thăm dò khác nhau như Thăm dò tuyến tính (Linear Probing), Thăm dò bậc hai (Quadratic Probing) và Băm kép (Double Hashing).
- Thăm dò tuyến tính (Linear Probing): Nếu chỉ mục
ibị đụng độ, kiểm tra các chỉ mụci+1, i+2, i+3, ...(modulo kích thước mảng) cho đến khi tìm thấy một bucket trống. - Thăm dò bậc hai (Quadratic Probing): Nếu chỉ mục
ibị đụng độ, kiểm trai+1^2, i+2^2, i+3^2, ...(modulo kích thước mảng). - Băm kép (Double Hashing): Sử dụng một hàm băm thứ hai để xác định bước nhảy khi thăm dò.
Ưu điểm của Open Addressing là không cần thêm cấu trúc dữ liệu phụ, giúp tiết kiệm bộ nhớ. Nhược điểm là phức tạp hơn khi triển khai, dễ bị hiện tượng “gom nhóm” (clustering) làm giảm hiệu suất, và việc xóa phần tử phức tạp hơn (cần đánh dấu “đã xóa” thay vì xóa hẳn). Nó cũng đòi hỏi tỉ lệ tải phải thấp để đảm bảo có chỗ trống.
Ưu điểm và nhược điểm của Hash table
Hash table là một cấu trúc dữ liệu mạnh mẽ, nhưng cũng có những hạn chế riêng. Việc hiểu rõ ưu điểm và nhược điểm giúp bạn quyết định khi nào nên sử dụng nó một cách hiệu quả.
Ưu điểm:
- Tốc độ truy xuất dữ liệu cực nhanh: Đây là ưu điểm lớn nhất. Trung bình, các thao tác tìm kiếm, chèn và xóa chỉ mất thời gian không đổi O(1), làm cho Hash table trở thành lựa chọn hàng đầu cho các ứng dụng đòi hỏi hiệu suất cao.
- Hiệu quả với lượng dữ liệu lớn: Nhờ tốc độ O(1), hiệu suất của Hash table ít bị ảnh hưởng khi số lượng phần tử tăng lên (trong trường hợp không có quá nhiều đụng độ và tỉ lệ tải thấp).
Nhược điểm:
- Hiệu năng phụ thuộc lớn vào hàm băm: Nếu hàm băm không tốt hoặc dữ liệu đầu vào có tính “mẫu” (pattern), có thể xảy ra rất nhiều đụng độ, làm suy giảm hiệu năng tới O(n) trong trường hợp xấu nhất.
- Hiệu năng phụ thuộc vào tỉ lệ tải (Load Factor): Khi Hash table đầy dần, tỉ lệ tải tăng cao, khả năng đụng độ tăng lên và hiệu năng giảm xuống. Cần phải thực hiện “resizing” (tăng kích thước bảng và băm lại toàn bộ dữ liệu) khi tỉ lệ tải vượt ngưỡng, quá trình này tốn kém thời gian.
- Không duy trì thứ tự: Các phần tử trong Hash table không được lưu trữ theo bất kỳ thứ tự cụ thể nào (ví dụ: theo thứ tự của Key). Điều này gây khó khăn nếu bạn cần duyệt qua các phần tử theo thứ tự tăng dần hoặc giảm dần.
- Khó khăn khi duyệt/lặp: Do cách lưu trữ phân tán, việc duyệt qua tất cả các phần tử trong Hash table có thể kém hiệu quả hơn so với các cấu trúc dữ liệu có thứ tự hoặc liền mạch.
Độ phức tạp thời gian (Time Complexity) của Hash table
Độ phức tạp thời gian mô tả hiệu suất của các thao tác dựa trên kích thước dữ liệu (n). Đối với Hash table, chúng ta xét độ phức tạp trung bình (average case) và xấu nhất (worst case).
Trung bình (Average Case): O(1)
Trong trường hợp lý tưởng, khi hàm băm phân phối các khóa đều khắp các bucket và ít đụng độ xảy ra, các thao tác tìm kiếm, chèn và xóa chỉ mất một lượng thời gian không đổi, không phụ thuộc vào số lượng phần tử n. Điều này là do hàm băm đưa bạn thẳng đến bucket chứa phần tử cần tìm (hoặc chỗ trống để chèn).
Ví dụ: Tìm kiếm một từ trong từ điển Hash table. Hàm băm đưa bạn trực tiếp đến bucket chứa từ đó, và bạn chỉ cần kiểm tra một số lượng nhỏ các phần tử trong bucket (nếu có đụng độ).
Xấu nhất (Worst Case): O(n)
Trường hợp xấu nhất xảy ra khi tất cả hoặc gần như tất cả các khóa băm ra cùng một chỉ mục. Điều này biến bucket tại chỉ mục đó thành một danh sách rất dài (trong Separate Chaining) hoặc gây ra chuỗi thăm dò rất dài (trong Open Addressing).
Khi đó, để tìm, chèn hoặc xóa một phần tử, hệ thống có thể phải duyệt qua tất cả n phần tử trong danh sách dài đó (hoặc đi qua n bước thăm dò). Lúc này, độ phức tạp thời gian suy biến thành O(n), tương tự như duyệt qua một danh sách liên kết hoặc mảng không sắp xếp.
Trường hợp xấu nhất này thường hiếm xảy ra với hàm băm tốt và tỉ lệ tải được quản lý, nhưng là rủi ro tiềm ẩn cần lưu ý.
Khi nào nên sử dụng Hash table? (Các trường hợp ứng dụng)
Hash table là lựa chọn tối ưu cho nhiều bài toán và ứng dụng trong lập trình, đặc biệt khi yêu cầu tốc độ truy xuất nhanh dựa trên một “khóa” duy nhất.
- Xây dựng Từ điển (Dictionary) hoặc Bản đồ (Map): Đây là ứng dụng phổ biến nhất. Các cấu trúc dữ liệu như
dicttrong Python,HashMaptrong Java,unordered_maptrong C++ đều được triển khai dựa trên Hash table. Chúng cho phép bạn lưu trữ và lấy giá trị theo khóa một cách hiệu quả. - Triển khai Tập hợp (Set): Set là tập hợp các phần tử duy nhất. Hash table có thể được dùng để kiểm tra nhanh chóng liệu một phần tử có tồn tại trong tập hợp hay chưa (thao tác tìm kiếm O(1)).
- Caching: Sử dụng Hash table để lưu trữ dữ liệu truy cập gần đây hoặc thường xuyên. Khi cần dữ liệu, bạn kiểm tra cache (Hash table) trước. Nếu dữ liệu có sẵn, bạn lấy nó ngay lập tức (O(1)) thay vì thực hiện thao tác tốn kém hơn (ví dụ: đọc từ đĩa, gọi API).
- Đếm tần suất (Frequency Counting): Khi cần đếm số lần xuất hiện của các mục trong một danh sách, bạn có thể dùng Hash table. Key là mục cần đếm, Value là số lần xuất hiện. Duyệt qua danh sách, với mỗi mục, tìm nó trong Hash table (O(1)). Nếu có, tăng bộ đếm (Value); nếu không, thêm mới mục đó với bộ đếm là 1.
- Lập chỉ mục (Indexing): Trong cơ sở dữ liệu hoặc hệ thống file, Hash table có thể được sử dụng để tạo chỉ mục cho các bản ghi, cho phép truy xuất bản ghi dựa trên một trường (Key) rất nhanh.
- Kiểm tra sự tồn tại của phần tử: Nếu bạn chỉ cần biết liệu một phần tử có tồn tại trong một bộ sưu tập lớn hay không, mà không cần quan tâm đến thứ tự, Hash table là một lựa chọn tuyệt vời nhờ tốc độ tìm kiếm O(1).
Hash table khác gì Hash map?
Một sự nhầm lẫn phổ biến là giữa thuật ngữ “Hash table” và “Hash Map”. Về mặt khái niệm, chúng đều đề cập đến cấu trúc dữ liệu lưu trữ Key-Value sử dụng kỹ thuật băm để truy xuất nhanh. Tuy nhiên, trong ngữ cảnh của các ngôn ngữ lập trình cụ thể, chúng có thể là các triển khai khác nhau với những đặc điểm riêng.
Ví dụ điển hình nhất là trong Java:
**Hashtable**: Là một lớp cũ hơn, được đồng bộ hóa (synchronized) sẵn. Điều này có nghĩa là nó an toàn khi sử dụng trong môi trường đa luồng (multiple threads) mà không cần đồng bộ hóa thủ công, nhưng đổi lại hiệu suất kém hơn vì chỉ một luồng có thể truy cập vào một thời điểm.Hashtablekhông cho phép Key hoặc Value lànull.**HashMap**: Là lớp mới hơn, không được đồng bộ hóa (non-synchronized) theo mặc định. Nó nhanh hơnHashtabletrong môi trường đơn luồng.HashMapcho phép một Key lànullvà nhiều Value lànull.
Do đó, khi nói về “Hash table” như một cấu trúc dữ liệu lý thuyết, nó bao gồm cả khái niệm HashMap. Nhưng khi làm việc với một ngôn ngữ cụ thể, bạn cần hiểu rõ sự khác biệt giữa các lớp triển khai của nó.
Ví dụ đơn giản về Hash table
Để giúp bạn dễ hình dung, chúng ta hãy xem một ví dụ đơn giản về cách Hash table hoạt động ở mức khái niệm.
Ví dụ Minh họa bằng Analogy (Tủ Hồ Sơ):
Hãy tưởng tượng bạn có một tủ hồ sơ với 26 ngăn kéo, mỗi ngăn được đánh dấu bằng một chữ cái từ A đến Z. Đây chính là các “bucket” của bạn.
Bạn muốn lưu trữ thông tin liên lạc của bạn bè. Tên của bạn bè là “khóa” (Key), và thông tin liên lạc là “giá trị” (Value).
- Chèn (Insert): Để lưu thông tin của “Alice”, bạn dùng chữ cái đầu tiên của tên cô ấy (“A”) làm “hàm băm” đơn giản. Chữ “A” đưa bạn đến ngăn kéo “A”. Bạn đặt hồ sơ của Alice vào ngăn kéo đó. Nếu sau đó bạn lưu “Andrew”, bạn cũng đặt hồ sơ của Andrew vào ngăn “A”. (Đây là một dạng đụng độ đơn giản).
- Tìm kiếm (Search): Để tìm thông tin của “Bob”, bạn dùng chữ “B” (hàm băm) để đi thẳng đến ngăn kéo “B”. Sau đó, bạn chỉ cần lục trong ngăn kéo “B” để tìm hồ sơ mang tên Bob.
Ưu điểm là bạn không cần phải lục qua toàn bộ 26 ngăn kéo; bạn chỉ cần mở đúng ngăn theo chữ cái đầu. Tuy nhiên, nếu có quá nhiều người cùng chữ cái đầu (nhiều đụng độ), việc tìm kiếm trong ngăn kéo đó sẽ mất nhiều thời gian hơn.
Ví dụ Minh họa bằng Code (Python Dictionary):
Python dict là một ví dụ điển hình về Hash table. Bạn không cần quan tâm đến hàm băm hay bucket cụ thể, ngôn ngữ sẽ xử lý giúp bạn.
Python
# Tạo một Hash table (Dictionary trong Python)
thong_tin_lien_lac = {}
# Chèn dữ liệu (Insert)
thong_tin_lien_lac['Alice'] = '0912345678'
thong_tin_lien_lac['Bob'] = 'bob@email.com'
thong_tin_lien_lac['Charlie'] = 'Địa chỉ X'
# Tìm kiếm dữ liệu (Search)
so_dien_thoai_alice = thong_tin_lien_lac['Alice'] # Rất nhanh, O(1) trung bình
print(f"Số điện thoại của Alice là: {so_dien_thoai_alice}")
# Chèn thêm (có thể gây đụng độ nội bộ)
thong_tin_lien_lac['Andrew'] = 'andrew@contact.net' # Python xử lý đụng độ
# Xóa dữ liệu (Delete)
del thong_tin_lien_lac['Bob'] # Rất nhanh, O(1) trung bình
# In toàn bộ nội dung (không theo thứ tự cố định)
print("\nThông tin liên lạc hiện tại:")
for ten, lien_lac in thong_tin_lien_lac.items():
print(f"{ten}: {lien_lac}")
# Kiểm tra sự tồn tại (O(1) trung bình)
if 'Charlie' in thong_tin_lien_lac:
print("\nCharlie có trong danh bạ.")
if 'David' not in thong_tin_lien_lac:
print("David không có trong danh bạ.")
Trong ví dụ này, tên ('Alice', 'Bob', 'Charlie') là Key, và thông tin liên lạc ('0912345678', 'bob@email.com', 'Địa chỉ X') là Value. Python sử dụng một hàm băm cho các chuỗi và quản lý các bucket để lưu trữ những cặp này, giúp các thao tác truy cập theo tên diễn ra cực kỳ nhanh chóng.