Cải thiện hiệu suất dự đoán trong học máy là mục tiêu quan trọng khi làm việc với các bài toán phức tạp. Boosting là một giải pháp mạnh mẽ, sử dụng cơ chế học tuần tự để khắc phục các sai sót từ các mô hình trước đó và tạo ra một mô hình học mạnh mẽ và chính xác hơn. Bài viết này sẽ giúp bạn tìm hiểu kỹ hơn về Boosting và các ứng dụng của nó.
Đọc bài viết dưới đây hoặc tìm hiểu thêm về cách hoạt động, các loại Boosting trong Machine Learning tại: Boosting là gì? Lợi ích của Boosting trong Machine Learning
Boosting là gì trong Machine Learning?
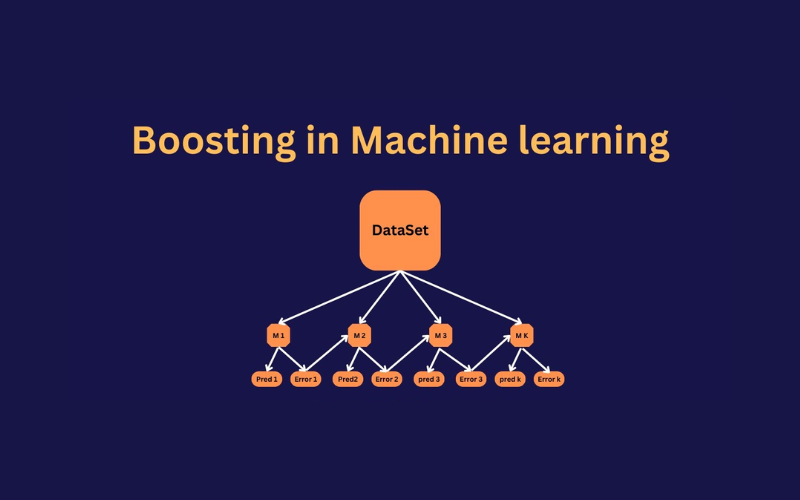
Boosting là một họ kỹ thuật học máy ensemble tiên tiến, hoạt động bằng cách xây dựng mô hình theo kiểu nối tiếp . Nó kết hợp nhiều mô hình dự đoán yếu (weak learners) lại với nhau để tạo thành một mô hình dự đoán mạnh (strong learner) duy nhất, với mục tiêu chính là tăng cường độ chính xác tổng thể .
Khác với các phương pháp song song như Bagging, điểm cốt lõi của Boosting là các mô hình sau học hỏi từ lỗi sai của các mô hình trước đó . Nó tập trung vào những điểm dữ liệu khó dự đoán, liên tục cải thiện hiệu năng qua từng vòng lặp, giống như một học sinh nỗ lực sửa chữa những lỗi sai của mình để ngày càng tiến bộ hơn.

Quá trình này thường liên quan đến việc gán trọng số cao hơn cho các mẫu bị dự đoán sai (như trong AdaBoost) hoặc huấn luyện mô hình mới để dự đoán phần lỗi còn lại (phần dư - residuals, như trong Gradient Boosting). Kết quả là một mô hình cuối cùng có khả năng giảm độ lệch (bias) rất hiệu quả và đạt hiệu năng ấn tượng.
Tầm quan trọng của thuật toán Boosting
Tầm quan trọng của Boosting nằm ở khả năng đạt được độ chính xác dự đoán cực kỳ cao , thường dẫn đầu trong nhiều bài toán Machine Learning, đặc biệt với dữ liệu dạng bảng. Nó đã đẩy xa giới hạn hiệu năng của các mô hình học máy truyền thống và trở thành một công cụ thiết yếu.
Các thuật toán Boosting, đặc biệt là các biến thể hiện đại như XGBoost, LightGBM, CatBoost, thường xuyên thống trị các cuộc thi khoa học dữ liệu lớn như Kaggle. Điều này chứng tỏ sức mạnh và hiệu quả vượt trội của chúng trong việc xử lý các bộ dữ liệu phức tạp và tìm ra các mẫu ẩn tinh vi.
Sự thành công này không chỉ giới hạn trong môi trường học thuật hay thi đấu. Boosting đóng vai trò quan trọng trong việc nâng cao chất lượng của nhiều ứng dụng thực tế đòi hỏi độ chính xác cao, từ việc xếp hạng kết quả tìm kiếm, phát hiện gian lận tài chính, đến chẩn đoán y khoa, góp phần tạo ra các hệ thống thông minh và đáng tin cậy hơn.
Hơn nữa, việc nghiên cứu và phát triển các kỹ thuật Boosting cũng thúc đẩy sự hiểu biết sâu sắc hơn về các khái niệm nền tảng như bias-variance tradeoff, tối ưu hóa hàm mất mát và vai trò của việc điều chuẩn (regularization). Nó là minh chứng cho sức mạnh của việc kết hợp thông minh nhiều thành phần yếu để tạo ra một tổng thể mạnh mẽ.
Ưu và nhược điểm của thuật toán Boosting trong Machine Learning
Giống như mọi kỹ thuật mạnh mẽ khác, Boosting mang trong mình cả những ưu điểm vượt trội lẫn những hạn chế nhất định . Hiểu rõ hai mặt này giúp chúng ta áp dụng Boosting một cách hiệu quả và đưa ra quyết định đúng đắn khi lựa chọn mô hình cho bài toán cụ thể đang đối mặt.
Nhìn chung, Boosting nổi bật với khả năng đạt độ chính xác cao và giảm bias hiệu quả . Tuy nhiên, nó cũng đòi hỏi sự cẩn trọng trong việc tinh chỉnh, nhạy cảm hơn với nhiễu và có thể khó diễn giải hơn so với các mô hình đơn giản khác. Chúng ta hãy cùng đi sâu vào từng khía cạnh.
Ưu điểm của Boosting
Điểm mạnh lớn nhất và được công nhận rộng rãi nhất của Boosting chính là khả năng mang lại độ chính xác dự đoán vượt trội . Trong nhiều bài toán phân loại và hồi quy, đặc biệt là với dữ liệu dạng bảng (tabular data), các mô hình Boosting thường cho kết quả tốt hơn đáng kể so với nhiều thuật toán khác, kể cả Deep Learning trong một số trường hợp.
Khả năng này xuất phát từ cơ chế học tuần tự, tập trung sửa lỗi và giảm độ lệch (bias) rất hiệu quả. Boosting có thể biến những mô hình cơ sở rất yếu, chỉ nhỉnh hơn đoán mò một chút, thành một mô hình tổng hợp cực kỳ mạnh mẽ, nắm bắt được các mối quan hệ phức tạp trong dữ liệu mà các mô hình đơn giản có thể bỏ lỡ.
Bên cạnh đó, các thuật toán như Gradient Boosting còn mang đến tính linh hoạt cao trong việc lựa chọn hàm mất mát (loss function). Điều này cho phép tùy chỉnh mô hình phù hợp hơn với mục tiêu cụ thể của bài toán, không chỉ giới hạn ở các hàm mất mát tiêu chuẩn. Khả năng này mở rộng phạm vi ứng dụng của Boosting.
Các biến thể hiện đại như XGBoost, LightGBM, CatBoost còn được tối ưu hóa mạnh mẽ về hiệu năng tính toán và bổ sung nhiều tính năng hữu ích. Chúng tích hợp sẵn các kỹ thuật điều chuẩn (regularization) tinh vi để chống overfitting, có khả năng xử lý giá trị thiếu một cách thông minh và thậm chí xử lý biến phân loại trực tiếp (CatBoost), giúp đơn giản hóa quá trình chuẩn bị dữ liệu.
Nhược điểm của Boosting
Một trong những thách thức chính khi sử dụng Boosting là độ nhạy cảm cao với dữ liệu nhiễu (noise) và các điểm ngoại lệ (outliers) . Do cơ chế tập trung vào các lỗi sai, nếu trong dữ liệu có nhiều điểm nhiễu hoặc ngoại lệ, mô hình Boosting có thể cố gắng “học” cả những điểm này, dẫn đến hiện tượng overfitting và giảm khả năng tổng quát hóa.
Chính vì vậy, Boosting cũng dễ bị overfitting hơn so với Bagging nếu không được kiểm soát cẩn thận. Việc lựa chọn đúng số lượng vòng lặp (số mô hình yếu), giới hạn độ phức tạp của mô hình yếu, sử dụng learning rate phù hợp và áp dụng các kỹ thuật điều chuẩn là cực kỳ quan trọng để ngăn chặn overfitting khi dùng Boosting.
Một hạn chế khác đến từ bản chất học tuần tự . Việc mô hình sau phải chờ kết quả của mô hình trước làm hạn chế khả năng song song hóa quá trình huấn luyện. Mặc dù các thư viện hiện đại đã có nhiều cải tiến, thời gian huấn luyện Boosting vẫn có thể lâu hơn đáng kể so với Bagging, đặc biệt trên các bộ dữ liệu rất lớn.
Cuối cùng, Boosting thường có nhiều siêu tham số (hyperparameters) cần phải tinh chỉnh để đạt hiệu năng tối ưu (ví dụ: learning rate, n_estimators, max_depth, subsample, các tham số regularization…). Quá trình tìm kiếm bộ siêu tham số tốt nhất có thể tốn nhiều thời gian và tài nguyên tính toán. Đồng thời, giống như các mô hình ensemble phức tạp khác, tính diễn giải (interpretability) của mô hình Boosting thường thấp.
Ứng dụng của Boosting hiện nay
Với khả năng đạt độ chính xác cao, các thuật toán Boosting được ứng dụng rộng rãi trong nhiều lĩnh vực quan trọng , đặc biệt là những nơi mà hiệu năng dự đoán chính xác mang lại giá trị lớn hoặc giúp giải quyết các bài toán phức tạp một cách hiệu quả hơn so với các phương pháp truyền thống.
Từ các công cụ tìm kiếm hàng đầu thế giới đến các hệ thống tài chính phức tạp, dấu ấn của Boosting hiện diện khắp nơi. Nó giúp tối ưu hóa quy trình , đưa ra quyết định thông minh hơn dựa trên dữ liệu và tạo ra lợi thế cạnh tranh trong nhiều ngành công nghiệp khác nhau nhờ vào sức mạnh dự đoán vượt trội của mình.
Trong lĩnh vực công nghệ tìm kiếm , các biến thể của Gradient Boosting đóng vai trò quan trọng trong việc xếp hạng các trang web trong kết quả trả về cho người dùng. Chúng giúp xác định trang nào phù hợp nhất với truy vấn tìm kiếm, mang lại trải nghiệm tốt hơn và thông tin liên quan hơn cho hàng tỷ lượt tìm kiếm mỗi ngày.
Ngành tài chính và ngân hàng cũng ứng dụng mạnh mẽ Boosting. Các mô hình này được dùng để phát hiện giao dịch gian lận với độ chính xác cao, đánh giá rủi ro tín dụng của khách hàng để đưa ra quyết định cho vay phù hợp, hay dự báo biến động thị trường , hỗ trợ các nhà đầu tư đưa ra chiến lược hiệu quả.
Trong thương mại điện tử và marketing , Boosting giúp dự đoán hành vi khách hàng , như khả năng họ sẽ mua một sản phẩm (propensity modeling) hay rời bỏ dịch vụ (churn prediction). Nó cũng được dùng để tối ưu hóa hệ thống gợi ý sản phẩm hoặc dự đoán tỷ lệ nhấp chuột (CTR) vào quảng cáo, giúp tăng doanh thu và hiệu quả chiến dịch.
Mặc dù cần cẩn trọng về tính diễn giải, Boosting cũng được khám phá ứng dụng trong y sinh để hỗ trợ chẩn đoán bệnh hoặc phân loại các mẫu sinh học . Ngoài ra, nó là công cụ quen thuộc và cực kỳ hiệu quả trong các cuộc thi khoa học dữ liệu như Kaggle, thường xuyên là thành phần chính trong các giải pháp chiến thắng.