Tăng cường tính ổn định cho các mô hình học máy là một yếu tố quan trọng để cải thiện độ chính xác. Bagging (Bootstrap Aggregating) là một phương pháp Ensemble Learning hiệu quả, giúp giải quyết vấn đề này. Bằng cách tạo ra nhiều tập dữ liệu huấn luyện con và tổng hợp kết quả, Bagging giúp nâng cao hiệu suất của mô hình. Bài viết này sẽ cung cấp cho bạn cái nhìn sâu sắc về Bagging và các ứng dụng thực tế của nó.
Bạn có thể tham khảo bài viết dưới đây, hoặc tìm hiểu chi tiết hơn về Bagging trong Machine Learning tại: Bagging là gì? Tìm hiểu về Bagging trong Machine Learning
Bagging là gì trong Machine Learning?
Bagging, viết tắt của Bootstrap Aggregating, là một kỹ thuật học máy ensemble nhằm cải thiện độ chính xác và ổn định của mô hình. Nó hoạt động bằng cách kết hợp dự đoán từ nhiều mô hình cơ sở được huấn luyện trên các tập dữ liệu con khác nhau, tạo ra từ tập dữ liệu gốc thông qua lấy mẫu bootstrap.
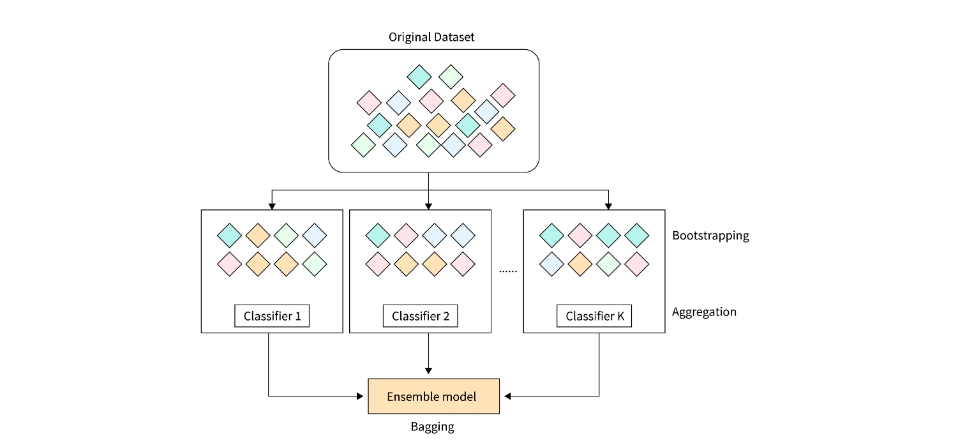
Mục tiêu chính của kỹ thuật này là giảm phương sai (variance), một yếu tố thường gây ra hiện tượng overfitting (quá khớp) khi mô hình học quá chi tiết các đặc điểm của dữ liệu huấn luyện, dẫn đến khả năng tổng quát hóa kém trên dữ liệu mới. Bagging đặc biệt hiệu quả với các mô hình không ổn định.
Nguồn gốc và người đề xuất
Khái niệm Bagging không phải là mới mà đã có từ khá lâu trong cộng đồng học máy. Nó được chính thức giới thiệu bởi Leo Breiman, một nhà thống kê và khoa học máy tính lỗi lạc, trong bài báo khoa học “Bagging predictors” năm 1996. Công trình này đã đặt nền móng cho nhiều kỹ thuật ensemble sau này.
Sự ra đời của Bagging đánh dấu một bước tiến quan trọng trong việc cải thiện hiệu năng của các mô hình học máy. Nó cho thấy sức mạnh của việc kết hợp nhiều mô hình “yếu” hoặc không ổn định để tạo ra một mô hình tổng hợp “mạnh mẽ” và ổn định hơn, đặc biệt là trong việc giảm thiểu ảnh hưởng của phương sai.
Ý tưởng cốt lõi là việc lấy trung bình các dự đoán từ nhiều mô hình được huấn luyện trên các phiên bản hơi khác nhau của dữ liệu sẽ giúp làm “mượt” các biến động và sai số ngẫu nhiên. Đây là một nguyên tắc thống kê cơ bản được áp dụng rất thành công vào lĩnh vực Machine Learning nhờ Leo Breiman, giúp giải quyết bài toán khó về bias-variance tradeoff (đánh đổi độ lệch-phương sai).
Lợi ích nổi bật của Bagging trong học máy
Lợi ích chính và đáng kể nhất của Bagging là khả năng giảm phương sai (variance reduction) hiệu quả cho mô hình. Bằng cách huấn luyện nhiều mô hình trên các tập dữ liệu con khác nhau và tổng hợp kết quả, Bagging làm giảm độ nhạy của mô hình cuối cùng đối với những thay đổi nhỏ trong dữ liệu huấn luyện.
Điều này trực tiếp dẫn đến việc cải thiện độ ổn định và khả năng tổng quát hóa của mô hình trên những dữ liệu chưa từng thấy trước đây. Mô hình Bagging thường ít bị overfitting hơn so với một mô hình cơ sở phức tạp duy nhất, chẳng hạn như một cây quyết định rất sâu.
Giảm phương sai và chống Overfitting
Như đã nhấn mạnh, sức mạnh lớn nhất của Bagging nằm ở việc kiểm soát phương sai. Khi một mô hình cơ sở (như cây quyết định) quá phức tạp, nó có xu hướng “ghi nhớ” dữ liệu huấn luyện, bao gồm cả nhiễu, dẫn đến phương sai cao và overfitting. Mô hình hoạt động tốt trên tập huấn luyện nhưng lại kém hiệu quả trên dữ liệu mới.
Bagging giải quyết vấn đề này bằng cách tạo ra sự đa dạng trong quá trình huấn luyện. Mỗi mô hình cơ sở chỉ nhìn thấy một phần dữ liệu gốc (thông qua bootstrap sampling) và học theo một cách hơi khác nhau. Việc lấy trung bình hoặc bỏ phiếu đa số các dự đoán này giúp loại bỏ các biến động ngẫu nhiên và giữ lại xu hướng chung, ổn định hơn.
Kết quả là mô hình Bagging cuối cùng trở nên ít nhạy cảm hơn với các điểm dữ liệu cụ thể trong tập huấn luyện. Nó có khả năng tổng quát hóa tốt hơn, áp dụng hiệu quả cho các tình huống thực tế với dữ liệu mới, qua đó giảm thiểu đáng kể nguy cơ overfitting vốn là một thách thức lớn trong Machine Learning.
Cải thiện độ chính xác và ổn định
Việc giảm phương sai thường đi đôi với việc cải thiện độ chính xác tổng thể của mô hình. Mặc dù Bagging không trực tiếp giảm độ lệch (bias), nhưng bằng cách tạo ra một mô hình ổn định hơn, nó cho phép sử dụng các mô hình cơ sở phức tạp hơn (có bias thấp nhưng variance cao) mà không sợ overfitting quá mức.
Sự kết hợp này thường dẫn đến một mô hình cuối cùng có hiệu năng dự đoán tốt hơn so với chỉ sử dụng một mô hình cơ sở đơn lẻ. Mô hình Bagging trở nên đáng tin cậy hơn vì kết quả dự đoán của nó ít bị dao động khi dữ liệu huấn luyện thay đổi một chút hoặc khi gặp dữ liệu mới.
Hơn nữa, kỹ thuật Out-of-Bag (OOB) Estimation là một lợi ích độc đáo. Chúng ta có thể sử dụng khoảng 36.8% dữ liệu không được chọn trong mỗi lần bootstrap (OOB samples) để đánh giá hiệu năng của mô hình Bagging mà không cần dùng đến tập validation riêng. Điều này giúp tiết kiệm dữ liệu và cung cấp một ước lượng khách quan về khả năng tổng quát hóa.
Khả năng xử lý song song
Một ưu điểm thực tiễn quan trọng của Bagging là khả năng huấn luyện các mô hình cơ sở một cách song song. Do mỗi mô hình được huấn luyện độc lập trên một tập bootstrap sample riêng biệt, chúng ta có thể phân chia công việc này cho nhiều lõi CPU hoặc thậm chí nhiều máy tính khác nhau.
Điều này giúp giảm đáng kể tổng thời gian huấn luyện cần thiết, đặc biệt khi số lượng mô hình cơ sở (n_estimators) lớn hoặc khi tập dữ liệu rất lớn. Khả năng song song hóa làm cho Bagging trở thành một lựa chọn hấp dẫn trong các ứng dụng đòi hỏi tốc độ huấn luyện nhanh hoặc khi làm việc với Big Data.
So với các phương pháp ensemble tuần tự như Boosting (ví dụ: AdaBoost, Gradient Boosting), nơi mô hình sau phải chờ kết quả của mô hình trước, Bagging có lợi thế rõ rệt về tốc độ huấn luyện nhờ tính chất song song này. Đây là một yếu tố quan trọng cần cân nhắc khi lựa chọn kỹ thuật ensemble phù hợp cho bài toán.
Những thách thức chính của Bagging trong Machine Learning
Mặc dù mang lại nhiều lợi ích, thách thức lớn nhất của Bagging là việc làm giảm tính diễn giải (interpretability) của mô hình. Thay vì một mô hình đơn lẻ (như một cây quyết định) có thể dễ dàng hình dung và giải thích các quy tắc dự đoán, mô hình Bagging là một “hộp đen” kết hợp hàng trăm hoặc hàng ngàn mô hình con.
Điều này gây khó khăn trong việc hiểu rõ tại sao mô hình đưa ra một quyết định cụ thể, yếu tố rất quan trọng trong nhiều lĩnh vực như tài chính hay y tế, nơi việc giải thích được lý do đằng sau dự đoán là bắt buộc. Sự đánh đổi giữa độ chính xác và khả năng diễn giải là điều cần cân nhắc kỹ lưỡng.
Mất tính diễn giải
Như đã đề cập, việc kết hợp nhiều mô hình cơ sở khiến mô hình Bagging cuối cùng trở nên phức tạp và khó hiểu hơn đáng kể so với một mô hình đơn lẻ. Ví dụ, việc diễn giải một rừng gồm 500 cây quyết định (như trong Random Forest, một biến thể của Bagging) là gần như không thể đối với con người.
Chúng ta có thể biết được dự đoán cuối cùng, nhưng việc truy ngược lại con đường logic dẫn đến dự đoán đó trở nên rất khó khăn. Điều này hạn chế việc áp dụng Bagging trong các ngành yêu cầu tính minh bạch cao hoặc cần phải giải trình các quyết định của mô hình cho người dùng hoặc cơ quan quản lý.
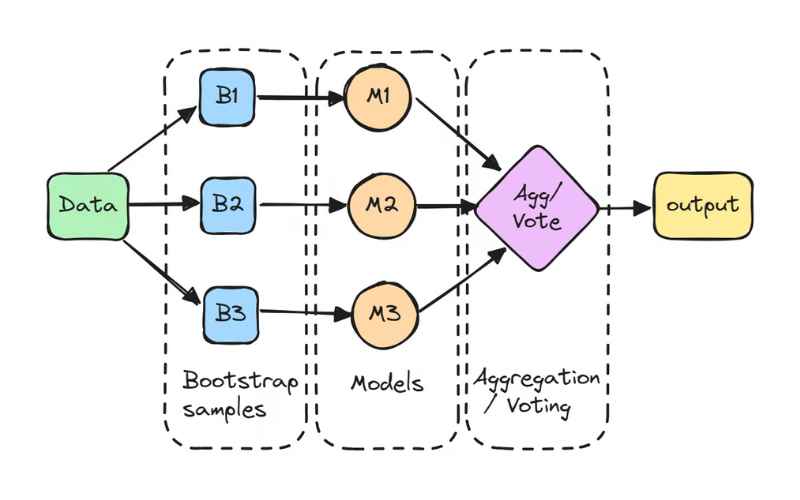
Mặc dù có một số kỹ thuật như đo lường tầm quan trọng của thuộc tính (feature importance) có thể cung cấp một số hiểu biết về cách mô hình hoạt động ở mức độ tổng thể, chúng vẫn không thể thay thế hoàn toàn khả năng diễn giải chi tiết của một mô hình đơn giản như cây quyết định hay hồi quy tuyến tính.
Chi phí tính toán
Một thách thức khác là chi phí tính toán và tài nguyên bộ nhớ. Việc huấn luyện và lưu trữ M mô hình cơ sở thay vì chỉ một mô hình duy nhất đòi hỏi nhiều tài nguyên hơn. Nếu M lớn hoặc mô hình cơ sở phức tạp, thời gian huấn luyện (ngay cả khi song song hóa) và dung lượng lưu trữ có thể tăng lên đáng kể.
Đặc biệt là trong giai đoạn dự đoán (inference), mô hình Bagging cần chạy qua tất cả M mô hình cơ sở để đưa ra kết quả cuối cùng. Điều này có thể làm tăng độ trễ (latency) so với việc dự đoán bằng một mô hình đơn lẻ, ảnh hưởng đến các ứng dụng đòi hỏi phản hồi thời gian thực.
Do đó, cần cân nhắc giữa lợi ích về độ chính xác và sự gia tăng về chi phí tài nguyên khi quyết định sử dụng Bagging. Trong một số trường hợp, đặc biệt là với các thiết bị có tài nguyên hạn chế hoặc yêu cầu độ trễ thấp, một mô hình đơn lẻ được tối ưu hóa cẩn thận có thể là lựa chọn phù hợp hơn.
Hạn chế với mô hình ổn định và Bias
Bagging phát huy hiệu quả tốt nhất khi các mô hình cơ sở có phương sai cao (không ổn định). Nếu mô hình cơ sở đã vốn ổn định và có phương sai thấp (ví dụ: Naive Bayes, Linear Regression), việc áp dụng Bagging thường không mang lại nhiều cải thiện, thậm chí có thể làm giảm nhẹ hiệu năng.
Ngoài ra, Bagging chủ yếu tập trung vào việc giảm phương sai và không trực tiếp giải quyết vấn đề độ lệch (bias). Nếu mô hình cơ sở có bias cao (underfitting), mô hình Bagging kết hợp cũng sẽ thừa hưởng bias đó. Nó không thể biến một mô hình cơ sở yếu về mặt bias thành một mô hình mạnh mẽ hơn về khía cạnh này.
Vì vậy, việc lựa chọn mô hình cơ sở phù hợp là rất quan trọng. Cần đảm bảo mô hình cơ sở đủ phức tạp để có bias thấp, sau đó dùng Bagging để kiểm soát phương sai phát sinh từ sự phức tạp đó. Kết hợp Bagging với mô hình quá đơn giản (high bias) sẽ không mang lại kết quả tối ưu.
Ứng dụng thực tế của Bagging
Nhờ khả năng cải thiện độ chính xác và ổn định, Bagging và đặc biệt là biến thể phổ biến của nó, Random Forest, đã được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau. Kỹ thuật này tỏ ra hiệu quả trong cả bài toán phân loại và hồi quy, giúp giải quyết các vấn đề phức tạp trong thế giới thực.
Từ lĩnh vực tài chính, y tế đến thương mại điện tử và công nghệ nhận dạng, Bagging đóng góp vào việc xây dựng các hệ thống thông minh hơn, đưa ra dự đoán chính xác hơn và hỗ trợ con người trong việc ra quyết định dựa trên dữ liệu. Sự linh hoạt và hiệu quả đã khiến nó trở thành một công cụ không thể thiếu trong bộ công cụ của các nhà khoa học dữ liệu.
Trong lĩnh vực tài chính
Trong ngành tài chính, nơi mà độ chính xác và độ tin cậy của dự đoán là cực kỳ quan trọng, Bagging được sử dụng trong nhiều tác vụ. Một ứng dụng phổ biến là đánh giá rủi ro tín dụng, dự đoán khả năng khách hàng không thể trả nợ. Mô hình Bagging giúp đưa ra quyết định cho vay chính xác hơn.
Một ứng dụng quan trọng khác là phát hiện gian lận (fraud detection) trong các giao dịch thẻ tín dụng hoặc ngân hàng trực tuyến. Bằng cách phân tích các mẫu hành vi giao dịch, mô hình Bagging có thể xác định các giao dịch đáng ngờ với độ chính xác cao, giúp ngăn chặn tổn thất tài chính cho cả khách hàng và tổ chức.
Ngoài ra, Bagging còn được dùng trong dự báo giá cổ phiếu hoặc các chỉ số tài chính khác, mặc dù đây là một bài toán rất khó khăn do tính biến động cao của thị trường. Tuy nhiên, khả năng giảm phương sai của Bagging cũng góp phần tạo ra các mô hình dự báo ổn định hơn trong lĩnh vực này.
Trong Y sinh và Chăm sóc sức khỏe
Lĩnh vực y sinh và chăm sóc sức khỏe cũng chứng kiến nhiều ứng dụng thành công của Bagging. Kỹ thuật này giúp phân tích dữ liệu gen để xác định các gen liên quan đến bệnh tật hoặc dự đoán nguy cơ mắc bệnh di truyền, hỗ trợ các nhà nghiên cứu trong việc tìm ra phương pháp điều trị mới.
Trong chẩn đoán y khoa, Bagging có thể được sử dụng để xây dựng các mô hình dự đoán bệnh dựa trên triệu chứng lâm sàng, kết quả xét nghiệm hoặc hình ảnh y tế (ví dụ: phân loại khối u là lành tính hay ác tính từ ảnh chụp X-quang hoặc MRI). Việc cải thiện độ chính xác chẩn đoán có ý nghĩa sống còn đối với bệnh nhân.
Hơn nữa, Bagging còn hỗ trợ dự đoán hiệu quả của phác đồ điều trị hoặc tiên lượng bệnh cho bệnh nhân dựa trên các đặc điểm cá nhân. Điều này giúp bác sĩ đưa ra quyết định điều trị phù hợp hơn, hướng tới y học cá nhân hóa, nâng cao chất lượng chăm sóc sức khỏe cho cộng đồng.
Trong Thương mại và Công nghệ
Trong thương mại điện tử, Bagging (đặc biệt là Random Forest) thường được dùng để xây dựng hệ thống gợi ý sản phẩm (recommendation systems). Bằng cách phân tích lịch sử mua hàng và hành vi duyệt web của người dùng, mô hình có thể đề xuất những sản phẩm phù hợp, tăng trải nghiệm khách hàng và doanh số bán hàng.
Các công ty công nghệ cũng sử dụng Bagging trong phân loại văn bản (ví dụ: lọc thư rác, phân tích cảm xúc khách hàng từ các bài đánh giá) hoặc nhận dạng hình ảnh (ví dụ: tự động gắn thẻ người trong ảnh, nhận diện vật thể). Khả năng xử lý dữ liệu chiều cao tốt của Bagging là một lợi thế ở đây.
Ngoài ra, Bagging còn được ứng dụng trong việc dự đoán hành vi người dùng, chẳng hạn như dự đoán khách hàng nào có khả năng rời bỏ dịch vụ (churn prediction) hoặc dự đoán quảng cáo nào sẽ có tỷ lệ nhấp chuột cao nhất. Những thông tin này giúp doanh nghiệp tối ưu hóa chiến lược kinh doanh và marketing của mình.