Bạn đang tìm cách cải thiện mô hình học máy của mình? Ensemble Learning (Học tập tổ hợp) là phương pháp hiệu quả để làm điều đó. Bằng cách kết hợp các dự đoán từ nhiều mô hình khác nhau, kỹ thuật này có thể tạo ra kết quả vượt trội hơn so với việc chỉ sử dụng một mô hình đơn lẻ. Bài viết này sẽ cung cấp thông tin chi tiết về Ensemble Learning và các ứng dụng thực tế của nó.
Bạn có thể tìm hiểu thêm về ứng dụng của Ensemble Learning trong các lĩnh vực tại: Ensemble Learning là gì? A-Z về học tập tổ hợp trong học máy
Ensemble Learning là gì?
Ensemble Learning (hay Học tập tổ hợp) đề cập đến một kỹ thuật trong lĩnh vực học máy, nơi mà nhiều mô hình được đào tạo song song để cùng xử lý một bài toán chung. Sau đó, các kết quả dự đoán từ những mô hình này được tổng hợp lại nhằm cải thiện hiệu quả hoạt động chung của toàn hệ thống.
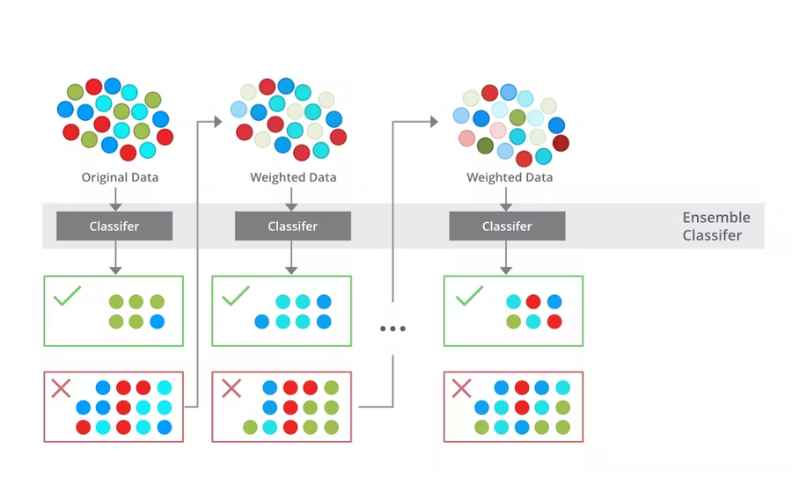
Nguyên tắc cơ bản đằng sau học tập tổ hợp là việc phối hợp nhiều mô hình khác nhau – với mỗi mô hình sở hữu những ưu và nhược điểm riêng – sẽ giúp hệ thống kết hợp này đạt được kết quả tốt hơn so với việc chỉ sử dụng một mô hình đơn lẻ bất kỳ. Học tập tổ hợp tìm thấy ứng dụng trong nhiều vấn đề của học máy, bao gồm phân loại (classification), hồi quy (regression), và phân cụm (clustering). Các kỹ thuật học tập tổ hợp thường gặp gồm có bagging, boosting, và stacking.
Trường hợp nên sử dụng Ensemble Learning?
Sau khi có cái nhìn tổng quan về Ensemble Learning, câu hỏi đặt ra là nên áp dụng nó khi nào? Học tập tổ hợp phát huy hiệu quả rõ rệt nhất trong những trường hợp dữ liệu có khả năng chứa nhiễu hoặc bị mất cân bằng.
Dữ liệu nhiễu (Noisy Data)
Dữ liệu nhiễu (Noisy Data) là những tập hợp dữ liệu mà trong đó tồn tại các sai sót, giá trị bất thường hoặc thông tin không pertinente, làm ẩn đi các quy luật quan trọng. Việc huấn luyện mô hình dựa trên dữ liệu như vậy thường khiến chúng khó khăn trong việc khái quát hóa hiệu quả, dẫn tới tình trạng phương sai cao – nghĩa là mô hình tuy hoạt động tốt với dữ liệu dùng để huấn luyện nhưng lại kém hiệu quả khi gặp dữ liệu mới chưa biết. Bagging và các kỹ thuật tổ hợp tương tự có khả năng khắc phục trở ngại này bằng cách huấn luyện nhiều mô hình riêng biệt trên các phần dữ liệu con khác nhau.
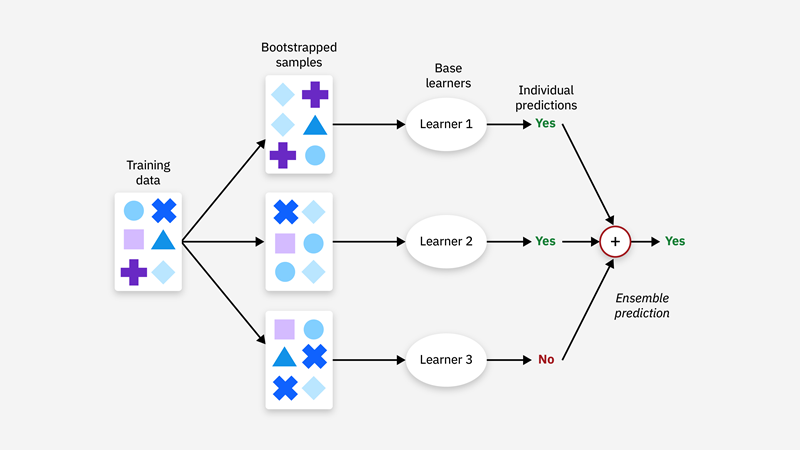
Mỗi mô hình sẽ học từ một khía cạnh dữ liệu có đôi chút khác biệt, và khi các dự đoán được tổng hợp lại, tác động tiêu cực của nhiễu sẽ giảm đi. Một ví dụ điển hình là Random Forest – một kỹ thuật bagging được ứng dụng rộng rãi – nó minh họa rõ ràng phương pháp này thông qua việc lấy giá trị trung bình từ các dự đoán của nhiều cây quyết định (decision tree). Điều này giúp mô hình tổng hợp cuối cùng trở nên ít nhạy cảm hơn với các giá trị ngoại lai và sai sót. Sự kết hợp này làm giảm phương sai, mang lại các dự đoán ổn định và đáng tin cậy hơn.
Tập dữ liệu mất cân bằng (Imbalanced Data Sets)
Ngược lại, tập dữ liệu mất cân bằng đặt ra một thử thách khác, đó là tình trạng một lớp (class) có số lượng mẫu vượt trội đáng kể so với các lớp còn lại. Chẳng hạn, trong việc phát hiện giao dịch gian lận, số lượng giao dịch hợp lệ thường áp đảo số lượng giao dịch gian lận. Một mô hình đơn giản có thể dễ dàng đạt độ chính xác cao bằng cách luôn dự đoán lớp đa số, nhưng lại bỏ qua hoàn toàn lớp thiểu số. Điều này gây ra độ chệch (bias) lớn – mô hình không nắm bắt được các đặc trưng quan trọng của lớp ít gặp hơn.
Các kỹ thuật boosting như AdaBoost và Gradient Boosting giải quyết vấn đề này bằng cách huấn luyện mô hình một cách tuần tự, trong đó mỗi mô hình tiếp theo tập trung vào các mẫu bị phân loại sai ở bước trước đó. Quá trình lặp lại này giúp mô hình học tốt hơn từ lớp thiểu số, từ đó giảm sai lệch (bias). Trong khi đó, phương pháp bagging cũng hỗ trợ bằng cách tạo ra các tập dữ liệu con cân bằng để huấn luyện, đảm bảo lớp thiểu số được thể hiện đầy đủ.
Ensemble Learning hoạt động như thế nào?
Học tập tổ hợp vận hành dựa trên các nguyên tắc chính sau đây:
- Phối hợp đa dạng mô hình: Các kỹ thuật tổ hợp tận dụng nhiều loại mô hình khác nhau (ví dụ: cây quyết định, SVM, v.v.), có thể thuộc cùng một loại hoặc khác loại. Thông qua việc tổng hợp các dự đoán từ chúng, kết quả thu được sẽ vững chắc hơn.
- Bagging: Kỹ thuật này bao gồm việc huấn luyện nhiều mô hình song song trên các bộ dữ liệu con khác nhau, được tạo ra bằng cách lấy mẫu ngẫu nhiên (có lặp lại) từ dữ liệu huấn luyện gốc. Mục đích là giảm phương sai và hạn chế tình trạng quá khớp (overfitting) thông qua việc lấy trung bình các dự đoán.
- Boosting: Ngược lại với Bagging, Boosting thực hiện huấn luyện các mô hình một cách tuần tự; mô hình sau sẽ được điều chỉnh để tập trung vào việc khắc phục những sai sót mà mô hình trước đó đã tạo ra. Cách tiếp cận này giúp nâng cao độ chính xác bằng việc giảm độ chệch (bias).
- Cơ chế bỏ phiếu: Đối với các bài toán phân loại, các phương pháp tổ hợp thường áp dụng một dạng bỏ phiếu theo đa số, trong đó, quyết định cuối cùng được đưa ra dựa trên lựa chọn phổ biến nhất từ các mô hình thành viên.
- Stacking: Kỹ thuật này liên quan đến việc huấn luyện một ‘siêu mô hình’ (meta-model) mới. Mô hình này học cách phối hợp tối ưu các dự đoán đầu ra từ nhiều mô hình cơ sở khác nhau.
Những ưu điểm của Ensemble Learning
Học tập tổ hợp được xem là một kỹ thuật hiệu quả cao trong học máy, hoạt động bằng cách phối hợp nhiều mô hình nhằm nâng cao hiệu suất và độ chính xác. Cách tiếp cận này tỏ ra đặc biệt hữu ích ở nhiều lĩnh vực do nó có thể cải thiện sự chính xác của dự đoán và hạn chế sai số. Một vài ưu điểm chính bao gồm:
- Cải thiện độ chính xác: Sự kết hợp các dự đoán từ nhiều mô hình thường dẫn đến kết quả vượt trội so với sử dụng một mô hình đơn lẻ.
- Nâng cao tính ổn định: Học tập tổ hợp góp phần hạn chế hiện tượng quá khớp (overfitting), qua đó xây dựng được những mô hình đáng tin cậy hơn, có khả năng hoạt động hiệu quả với dữ liệu mới.
- Độ linh hoạt cao: Những phương pháp tổ hợp như boosting và bagging có khả năng tương thích và áp dụng được cho nhiều loại thuật toán cũng như các dạng dữ liệu đa dạng.
- Hạn chế phương sai: Các kỹ thuật như bagging giúp làm giảm sự biến động của các dự đoán, nhờ vậy, kết quả đầu ra trở nên nhất quán hơn.
- Cải thiện khả năng khái quát hóa: Sự phối hợp của nhiều mô hình cho phép mô hình tổng thể học hỏi hiệu quả hơn khi gặp dữ liệu mới, điều này rất thích hợp cho các ứng dụng thực tiễn.
Một số nhược điểm của Ensemble Learning
Mặc dù học tập tổ hợp sở hữu nhiều ưu điểm, phương pháp này cũng đi kèm một số hạn chế đáng lưu tâm:
- Độ phức tạp gia tăng: Sự phối hợp của nhiều mô hình có thể làm cho toàn bộ hệ thống trở nên phức tạp hơn, đồng thời khó diễn giải hoạt động bên trong hơn.
- Yêu cầu thời gian huấn luyện lâu hơn: Quá trình đào tạo đồng thời nhiều mô hình đòi hỏi thời gian tính toán kéo dài hơn.
- Rủi ro quá khớp tiềm ẩn: Khi không được áp dụng một cách thận trọng, ngay cả các phương pháp tổ hợp cũng có khả năng bị quá khớp (overfit) dựa trên dữ liệu huấn luyện.